As we know, in recent years kubernetes has become an essential standard on container orchestration topic for our microservice architectures.
Although kubernetes solves many of our problems with its default usage, there are also some best practices and applications available that we can use to make our applications more stable, reliable and secure.
I have been working with kubernetes environment since 2017. Especially for the last 2 years, I have been experiencing kubernetes in the cloud environment. Of course, we made some mistakes in this process and we have also learned something from our mistakes. In this article context, I decided to gather some useful information altogether especially for the production environment.
I guess one of the most important topics is the good determination of the requirements when creating a kubernetes cluster.
While determining these requirements, it is necessary to answer the following questions:
The answers to these questions will give us some basic ideas about approximately how many nodes we will need and how the nodes specifications should be.
Of course, we are not done yet.
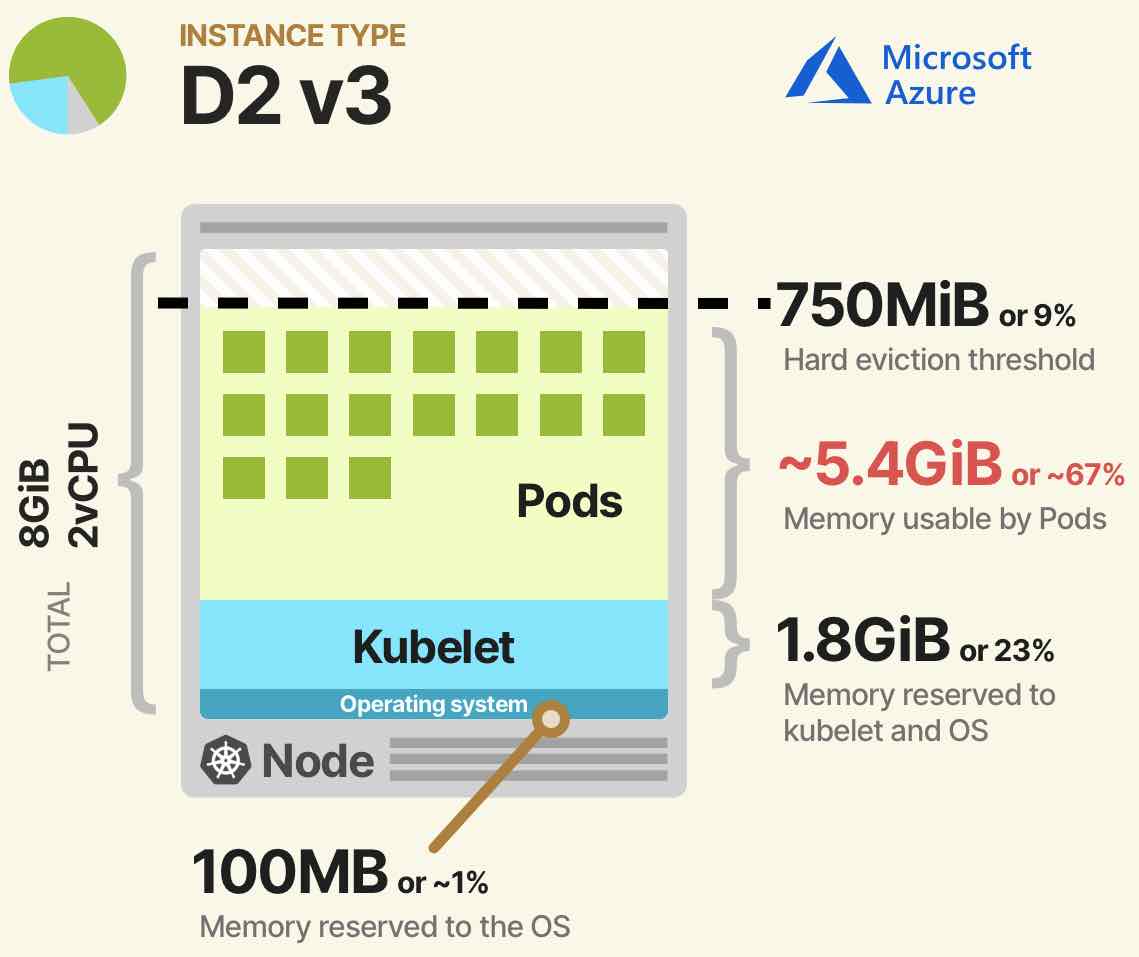
Another important topic is the allocatable resource in the cluster we will create. Unfortunately, we cannot use all the resources we have defined on a cluster such as CPU and memory as they are.
Some resources will be reserved for system daemons (OS, Eviction threshold). For example, Azure Kubernetes Service allocates 180 milicore of an 8 core machine. It also allows approximately 67% memory usage.
After determining the allocatable resource topic, it will be more clear what kind of cluster we will need.
So another important topic for the cloud environment is the determination of the networking model. For example, there are two different modes for Azure Kubernetes Service such as “Kubenet” and “Azure plugin”.
If we choose “Azure plugin” as the networking model due to different needs, it is necessary to calculate the subnet needs of the cluster. Because in this networking model, each pod will allocate a private IP address individually.
At this point, if we cannot make the calculation properly, it will be inevitable to encounter problems such as not be able to scale pods enough, update nodes or add new nodes due to the insufficient IP address in the subnet.
By using namespaces will give us a better isolation and management ability, especially if we are designing a cluster that many teams will work on. With namespaces, we can easily perform operations such as security and resource limitation in different contexts.
In addition to determining the needs of the cluster, there are also some points that we need to take into account in terms of applications and some configurations that we can do.
If you haven’t read it before, I suggest you first check out this article, where I have covered some principles that cloud-native applications should have.
First of all, we should not forget that the applications which we will deploy on kubernetes can be replaced with a new one or terminated at any time. In addition, it will be beneficial for us to develop our new applications by considering this approach.
So for this reason, especially for a production environment, we should not use the naked-pod on kubernetes. We just need to be aware of naked-pods will not be restarted in case of any error.
I think it is one of the best things that we can set the resource request limits of our deployments and keep them under control. Although the scalability capability of the kubernetes is a great feature, we should not forget that the applications, which are not properly configured, can cause applications in the cluster to fail.
After all, CPU and memory are power supplies for both our applications and the kubernetes scheduler.
By controlling the resource consumption of a pod, we can make sure that the system will be much more reliable. If we don’t, a pod can consume all the available resources.
There are two points that we need to consider.
We can do these definitions in the helm chart as below.
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "300m" NOTE: CPU resources can be defined in milicore type.
While determining the memory needs, we should not forget that the memory is not considered as a compressible resource and cannot be throttled. So when a pod reaches its memory limit, it will be terminated.
Another important topic for our applications to work properly is the usage of “liveness” and “readiness” probes in the scope of the health checks.
As we know, when a container get in the ready state, kubernetes starts to route traffic to the relavent pod. But the pod in the container may not be ready to accept traffic. Therefore, we need to specify “liveness” and “readiness” probes for applications in order kubernetes to do this process more efficiently.
By specifying the liveness probe, we tell kubernetes when it can restart the relavent container in case of any error. With readiness probe, we specify when the application will be ready to accept traffic.
It is also possible to set parameters such as “timeoutSeconds” or “initialDelaySeconds” in the probes when specifiying these probes.
livenessProbe:
httpGet:
path: /api/health
port: http
initialDelaySeconds: 20
timeoutSeconds: 30
readinessProbe:
httpGet:
path: /api/health
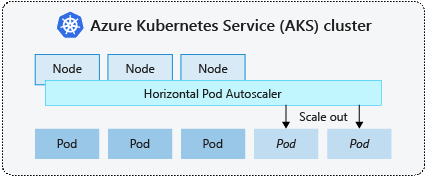
port: http I think HPA is a must-have feature for application we deploy to kubernetes. With HPA, it is possible to scale applications automatically.
It is also an ideal solution to use resources effectively.
So, in order to scale our applications according to CPU and memory metrics, we need to configure the helm chart of the related application as below.
“hpa.yaml” file should looks like:
{{- if .Values.hpa.enabled -}}
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: {{ include "testapp.fullname" . }}
namespace: {{ .Values.namespace }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ include "testapp.fullname" . }}
minReplicas: {{ .Values.hpa.minReplicas }}
maxReplicas: {{ .Values.hpa.maxReplicas }}
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: {{ .Values.hpa.targetCPUUtilizationPercentage }}
- type: Resource
resource:
name: memory
targetAverageValue: {{ .Values.hpa.targetMemoryAverageValue }}
{{- end}} Then, in the “values.yaml” file, we can set the auto-scale metrics as follows.
hpa: enabled: true minReplicas: 1 maxReplicas: 3 targetCPUUtilizationPercentage: 70 targetMemoryAverageValue: 256Mi
One of the important topics in terms of the consistency is the shutdown process of applications in a graceful way.
As we said before, applications on kubernetes are ephemeral. Containers can be terminated in any time such as auto-scaling, update operations or deletion of the pod.
During this termination process, the related pod may be performing some critical operations. In order to avoid such problems, our applications must handle the SIGTERM signal. When SIGTERM signal is sent, the relevant pod should shutdown itself in 30 sec by default. If the relevant pod does not shutdown itself during this time, then SIGKILL signal is sent and the relevant pod is terminated automatically.
In addition, we can customize the graceful termination period at the pod spec level in “deployment.yaml” file.
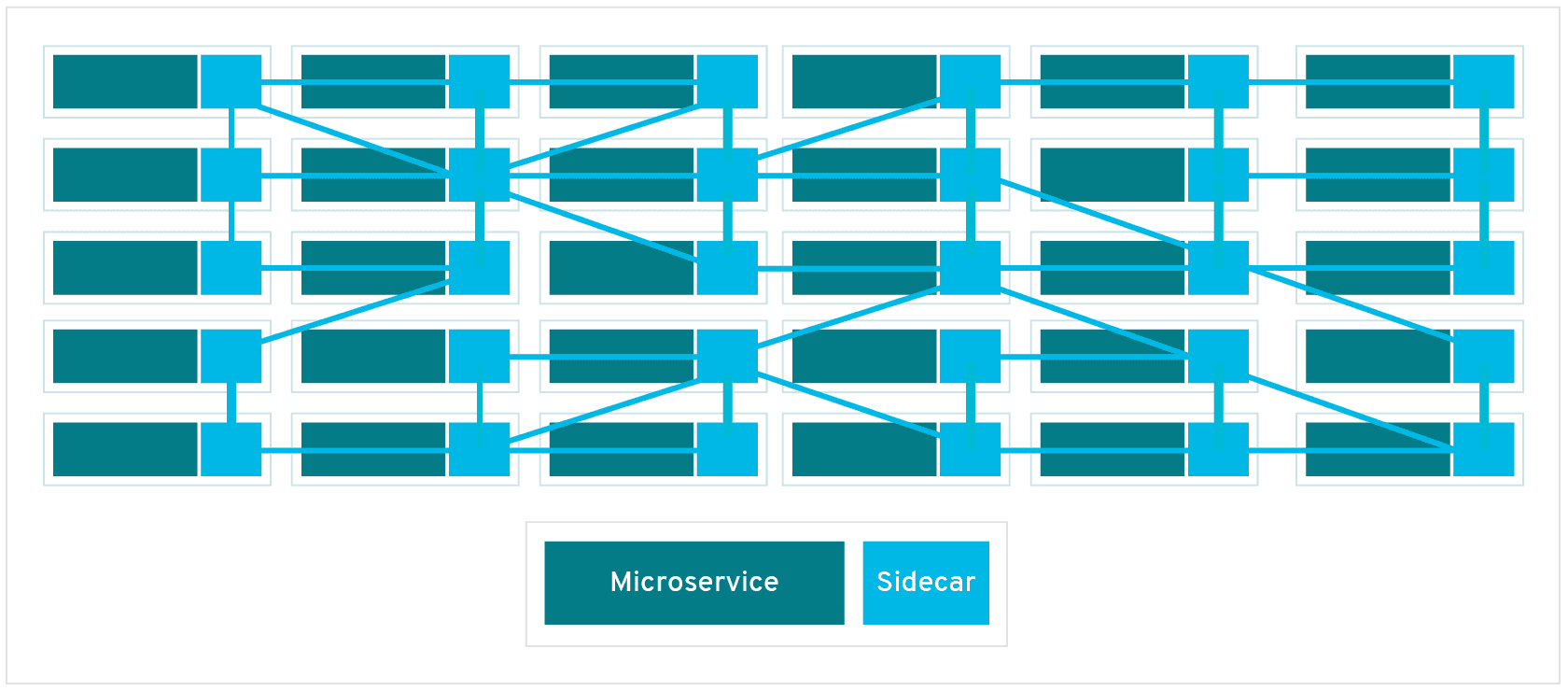
As we know, especially in the large-scale microservice ecosystem, service mesh technology plays a big role in service-to-service communication area.
If you are in a large organization, using a service mesh technology will be beneficial in terms of security, observability and durability. You can also reach my article on this topic from here.
Another benefit of service mesh is that it performs load-balancing operations for long-lived connections. When we use the keep-alive feature of the HTTP protocol, TCP connection stays open for the subsequent requests. I mean, the same pod handles the related requests. In fact, while we get benefit from throughput and latency, we lose scaling ability.
So, it is also possible to avoid such problems by using service mesh technology.
As we know, the security of containers under our responsibility. So, having a container security activity monitor such as Falco Project, which is hosted by CNCF, for production environment will be benefitical for us.
In this way, we can be aware of unexpected activities in our applications such as shell execution in a container or outbound network connections.
https://kubernetes.io/docs/concepts/configuration
https://learnk8s.io
Nowadays wherever I look, everyone talks about AI coding agents, agentic systems or LLM powered…
In the first two parts of this DevEx series, I tried to show how golden…
In the first part of this DevEx series, I tried to explain Platform Engineering and…
As an architect involved in platform engineering and DevEx transformation within a large-scale organization for…
{:en}In today’s technological age, we typically build our application solutions on event-driven architecture in order…
{:tr} Makalenin ilk bölümünde, Software Supply Chain güvenliğinin öneminden ve containerized uygulamaların güvenlik risklerini azaltabilmek…
{kind=link}
{kind=link}
{kind=link}
View Comments
süper bilgiler teşekürler hocam. Bu arada bir konu hakkında birşey sorucaktım. Bir microservice yapım var localde docker üzerinde çalıştırıyorum. Api gateway olarak Ocelot kullandım ama bu yapıyı Kubernetes e taşımak istiyorum. Api gateway olarak ocelot kullanmalı mıyım ? Ingress ile dışarıya açtım diyelim Gateway i ancak Ocelot tüm servicelere ip ile bağlanıyor direk veya docker compose daki service name ile.. Bunlara kubernetes service nameler ile bağlanmalıyım ki scale edebileyim. Burası karışık kafamda. ApiGateway kısmı nasıl olmalı sizce ?