As technology is constantly evolving and changing, the database schema of the application, that we work in, can also change with each new feature we implement. Therefore, we need to follow a migration strategy. In this way, the changes, that will be performed on domain models, can also be applied to the database schema.
In this article, I will try to show how we can perform migration operations of our applications on kubernetes environment by using kubernetes jobs.
I will use Docker Desktop’s Kubernetes feature as the development environment.
First of all, let’s take a look at the sample project which I prepared using .NET 5 and EF Core to demonstrate migration operations.
I created a console application called “Todo.DbMigration” to perform migration operations separately from the main application. Here, I simply implemented the “IDesignTimeDbContextFactory” interface using “TodoDbContext” that locates in the “Todo.Data” library.
using System.IO;
using Microsoft.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore.Design;
using Microsoft.Extensions.Configuration;
using Todo.Data;
namespace Todo.DbMigration
{
public class TodoDbContextFactory : IDesignTimeDbContextFactory<TodoDbContext>
{
public TodoDbContext CreateDbContext(string[] args)
{
var configuration = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json")
.AddEnvironmentVariables()
.Build();
var dbContextOptionsBuilder = new DbContextOptionsBuilder<TodoDbContext>();
var connectionString = configuration
.GetConnectionString("SqlConnectionString");
dbContextOptionsBuilder.UseSqlServer(connectionString, x => x.MigrationsAssembly("Todo.DbMigration"));
return new TodoDbContext(dbContextOptionsBuilder.Options);
}
}
} The db context in the “Todo.Data” library is as follows.
using Microsoft.EntityFrameworkCore;
using Todo.Data.Models;
namespace Todo.Data
{
public class TodoDbContext : DbContext
{
public TodoDbContext(DbContextOptions<TodoDbContext> options)
: base(options)
{
}
public DbSet<TodoEntity> Todos { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<TodoEntity>()
.HasKey(x => x.Id);
modelBuilder.Entity<TodoEntity>()
.Property(p => p.Name)
.HasMaxLength(150)
.IsRequired();
}
}
} To create the initial migration, I ran the following command in the root directory of the project.
dotnet ef migrations add InitialCreate --project ./Todo.Migration
Kubernetes Jobs offers us a way where we can run our finite operations. Just like how a controller “reschedules” or “restarts” a failed pod, a job also ensures that our finite operations run successfully.
If a pod created by a kubernetes job does not fail and exits successfully, the related job is considered as completed. We can check this by querying the “completion” status of the job we deployed.
Also when a job gets deleted, pods that are created by the job are also deleted automatically. But when a job is completed successfully, it does not get deleted automatically. So the deletion operations should be done manually by querying the completion status of the job. We will come to this point later.
In short, a kubernetes jobs are very useful especially for scenarios such as batch or migration.
I prefer to use helm for deployment processes because it increases productivity and provides reusability and standardization. That’s why we will use a helm chart for the job deployment.
First, we need to create a job helm chart template.
Now let’s go to the “helm-charts” path in the root folder of the project and create an initial helm chart template with the following command.
helm create migration-job
Then, we need to delete all the remaining files in the “templates” folders of the chart except “_helpers.tpl“.
Now we can define “job.yaml” file under the “templates” folder as follows.
apiVersion: batch/v1
kind: Job
metadata:
name: {{ include "migration-job.fullname" . }}
spec:
backoffLimit: 0
template:
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
restartPolicy: Never
{{- with .Values.nodeSelector }}
nodeSelector:
{{- toYaml . | nindent 8 }}
{{- end }} The parts we need to take into account here are restrartPolicy and backoffLimit. I set these policies to “0” and “Never” because I don’t want the pod/container to get restarted in case of any success or failure for operations such as migration. (Of course, this is also not guaranteed in some exceptional cases) Otherwise, the job will try to restart the failed pod again and again since the “backoffLimit” is set to “6” by default.
Also with this configuration, it will be easier for us to find out what caused the problem.
Let’s update the value file as follows.
image: repository: mytodoapp-migration tag: "v1" nodeSelector: beta.kubernetes.io/os: linux
So the helm chart template is ready. Now, all we have to do is to containerize the sample project with the “mytodoapp-migration:v1” tag.
We will use the Dockerfile which I prepared in the “Todo.DbMigration” project.
FROM mcr.microsoft.com/dotnet/runtime:5.0 AS base WORKDIR /app FROM mcr.microsoft.com/dotnet/sdk:5.0 AS build WORKDIR /src COPY ["Todo.DbMigration/Todo.DbMigration.csproj", "Todo.DbMigration/"] RUN dotnet restore "Todo.DbMigration/Todo.DbMigration.csproj" COPY . . WORKDIR "/src/Todo.DbMigration" RUN dotnet build "Todo.DbMigration.csproj" -c Release -o /app/build FROM build AS publish RUN dotnet publish "Todo.DbMigration.csproj" -c Release -o /app/publish FROM base AS final WORKDIR /app COPY --from=publish /app/publish . ENTRYPOINT ["dotnet", "Todo.DbMigration.dll"]
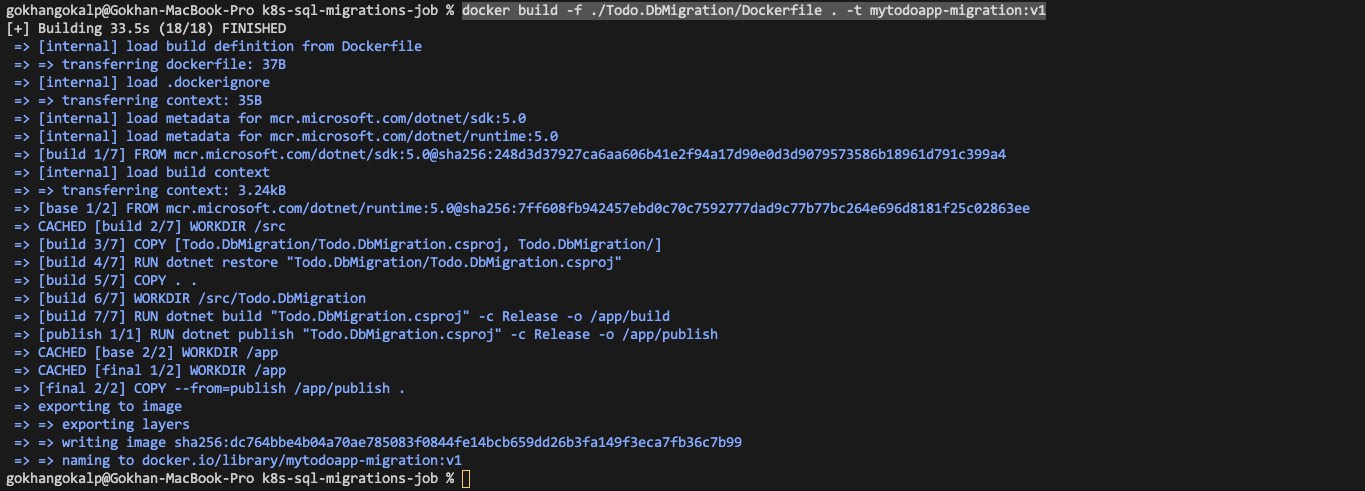
Now let’s containerize the migration application by running the following command in the root folder of the project.
docker build -f ./Todo.DbMigration/Dockerfile . -t mytodoapp-migration:v1
Now we can perform the deployment process since we have containerized the sample migration application.
For this, we need to run the following helm command in the “helm-charts” path.
helm upgrade --install --values ./migration-job/values.yaml mytodo-migration ./migration-job
So the migration application has been deployed.
First, let’s check if the job is successfully completed.
kubectl get job
As we can see, we can check whether it has been successfully completed or not by looking at the “COMPLETIONS” status of the migration application.
If any error occurred, we could also track the problem by looking at the logs of the corresponding pod created by the job.
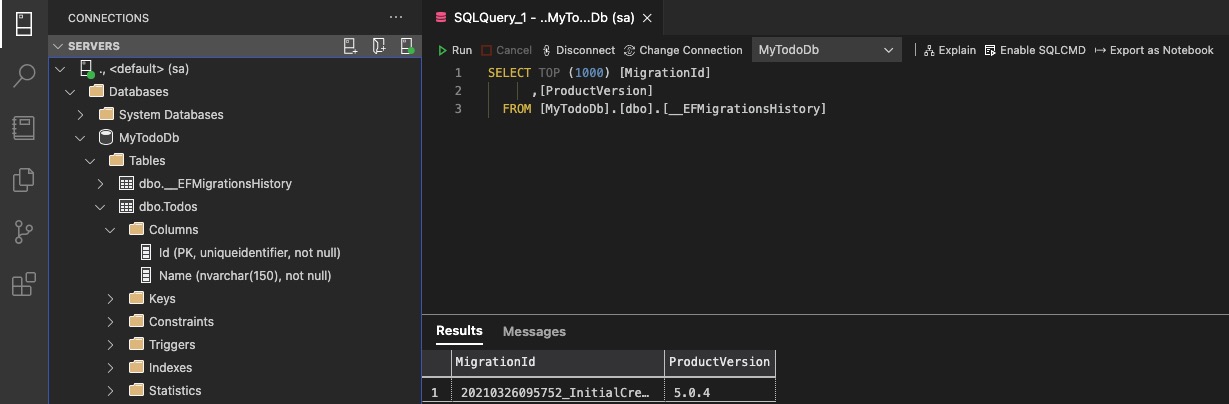
When we check the migration result by connecting to SQL Server, we can see that the related migration has been successfully applied.
We also mentioned that a job is not automatically deleted when it is completed. To perform the deletion operation, we can use the following standard helm command.
helm delete mytodo-migration
Well, let’s say we want to make these processes automated. For example, we are using Azure DevOps and we want the relevant migration job to get deleted automatically after successful completion.
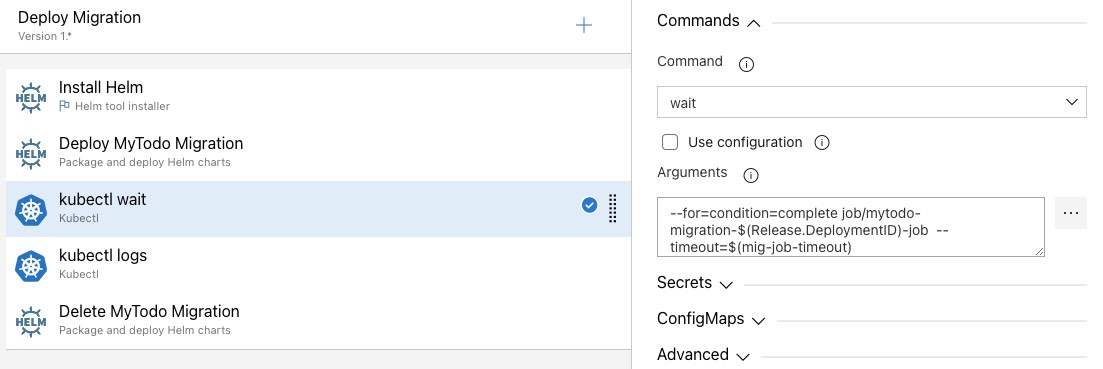
To do this, we can use the “wait” command of “kubectl“. In other words, before deleting the relevant job, we need to wait for it until it is completed.
We can do this with the help of the command below.
kubectl wait --for-condition=complete job/mytodo-migration-migration-job --timeout=2m
As we can see, the relevant task will be kept for the duration of the timeout until the condition we specified is met.
Unlike other pod controllers, a kubernetes job provides us a way that we can run one-time operations. We tried to simply take a look at how we can carry out operations such as migration in this way.
If we were not deploying the migration application independently from the main application, in other words, if we wanted to perform the migration operations at the same time with the main application, we could choose the init container or helm hook approaches according to use-case scenarios.
A job also has different usage scenarios and features. For example, we can control the execution time of a job with “activeDeadlineSeconds” parameter. To learn more about the job concept for different usage scenarios, you can check this link.
Nowadays wherever I look, everyone talks about AI coding agents, agentic systems or LLM powered…
In the first two parts of this DevEx series, I tried to show how golden…
In the first part of this DevEx series, I tried to explain Platform Engineering and…
As an architect involved in platform engineering and DevEx transformation within a large-scale organization for…
{:en}In today’s technological age, we typically build our application solutions on event-driven architecture in order…
{:tr} Makalenin ilk bölümünde, Software Supply Chain güvenliğinin öneminden ve containerized uygulamaların güvenlik risklerini azaltabilmek…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Thanks for this article. I want use a secret for storing connectionStrings. Unfortunately I can't this get to work. The connectstring isn't read from the secret and I can't figure out what went wrong. I created a generic secret which is working ok in my aspnetcore applications, but not in the configured job.
Please, can you help me. Thanks, Marcel
I have changed the job.yaml file like this
apiVersion: batch/v1
kind: Job
metadata:
name: migrations
labels:
app: migrations
spec:
backoffLimit: 0
template:
spec:
containers:
- name: migrations
image: marcelb/migrations:v13
imagePullPolicy: Always
env:
- name: "ASPNETCORE_ENVIRONMENT"
value: "staging"
volumeMounts:
- name: secrets
mountPath: /app/secret
readOnly: true
volumes:
- name: secrets
secret:
secretName: secret-appsettingsmyfirstblazorapplication
restartPolicy: Never
nodeSelector:
beta.kubernetes.io/os: linux