Bildiğimiz gibi son yıllarda container orchestration konusunda kubernetes, microservice mimarilerimiz için olmazsa olmaz bir standart haline gelmiş durumda.
Kubernetes her ne kadar default ayarları ile de bir çok problemimizi çözüyor olsada, uygulamalarımızın daha stable, reliable ve secure olabilmesi için yapabileceğimiz/kullanabileceğimiz bazı best practice’ler ve uygulamalar da mevcut.
2017 yılından bu yana kubernetes ortamında çalışıyorum. Özellikle son 2 yıldır ise cloud ortamında kubernetes’i deneyimlemekteyim. Elbette bu süreçte bir takım hatalar yaptık ve bu hatalardan bir takım deneyimler elde ettik. Bu makale kapsamında ise özellikle production ortamı için gerekli/faydalı bulduğum bazı bilgileri bir araya toplamaya karar verdim.
En önemli konulardan belki birisi de, bir kubernetes cluster’ı oluştururken gereksinimlerin iyi belirlenmesidir.
Bu gereksinimleri belirlerken de, aşağıdaki sorulara cevap vermek gerekir:
Bu soruların cevapları bize, ortalama kaç adet node’a ihtiyaç duyacağımızı ve node’ların özelliklerinin nasıl olması gerektiği konusunda bazı temel fikirler verecektir.
Tabi iş bununla bitmiyor.
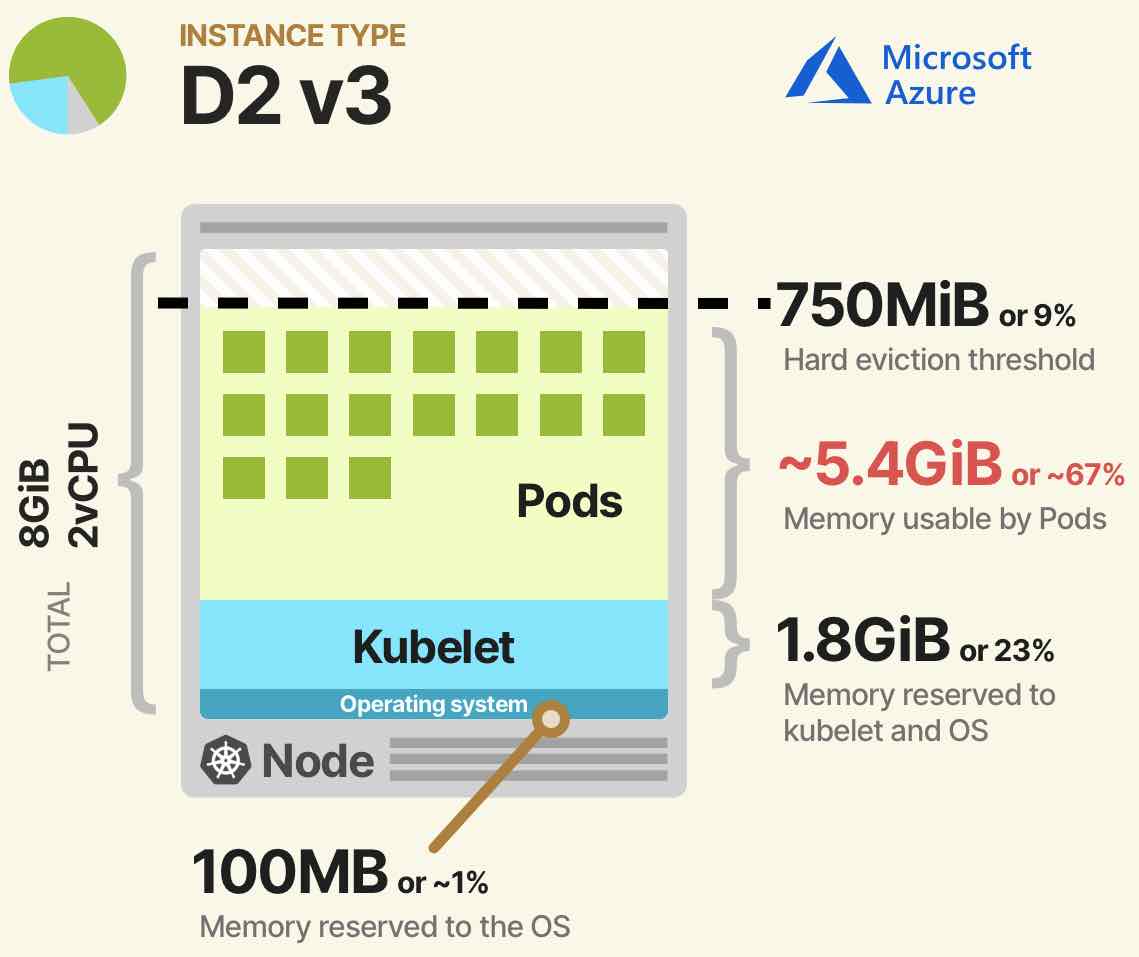
Bir diğer önemli konu ise, oluşturacağımız cluster içerisinde allocatable resource konusu. Maalesef ki bir cluster’a tanımlamış olduğumuz CPU ve Memory bazında tüm resource’ları olduğu tamamını gibi kullanamamaktayız.
Bir takım resource’lar system daemons (OS, Eviction threshold) için reserve edilecektir. Örneğin Azure Kubernetes ortamından konuşmak gerekirse, 8 core’lu bir makinenin 180 milicore’unu allocate etmektedir. 8GiB memory’de ise yaklaşık %67 lik bir memory kullanımına izin vermektedir.
Allocatable resource konusunu da belirledikten sonra, nasıl bir cluster’a ihtiyacımızın olacağı konusu daha çok netleşmiş olacaktır.
Cloud ortamı için önemli konulardan bir diğeri ise networking modelinin belirlenmesi. Örneğin, Azure Kubernetes için “Kubenet” ve “Azure plugin” olmak üzere iki farklı model bulunmakta.
Farklı ihtiyaçlardan dolayı networking modeli olarak “Azure plugin” seçersek, oluşturacak olduğumuz cluster’ın nasıl bir subnet’e sahip olması gerektiğini iyi hesaplamak gerekir. Çünkü bu networking modelinde, her bir pod bireysel olarak bir private IP adresi allocate edecektir.
Bu noktada hesaplamayı doğru yapamazsak, subnet içerisindeki IP adresi yetersizliğinden dolayı pod’ları yeterince scale edememe, node’ları güncelleyememe, yeni node ekleyememe gibi problemlerle karşılaşmamız kaçınılmaz olacaktır.
Özellikle bir çok takımın üzerinde çalışacağı bir cluster tasarlıyorsak, namespace’leri kullanmak bize daha iyi bir isolation ve yönetim kabiliyeti verecektir. Namespace’ler ile farklı context’lerde security ve resource limitleme gibi işlemleri kolaylıkla gerçekleştirebilmekteyiz.
Cluster ihtiyaçlarının belirlenmesi yanında, uygulama açısından da dikkat etmemiz gereken noktalar ve yapabileceğimiz bazı configuration’lar da mevcut.
Eğer daha önce okumadıysanız, ilk olarak cloud-native uygulamaların sahip olması gereken bir takım prensipleri ele aldığım şu makaleme göz atmanızı öneririm.
Öncelikle kubernetes üzerinde konumlandıracağımız uygulamaların fâni, yani her an kolaylıkla bir yenisi ile yer değiştirebileceğini unutmamamız gerekiyor. Ayrıca yeni geliştirdiğimiz uygulamaları, bu yaklaşımı düşünerek geliştirmemiz faydamıza olacaktır.
Bu sebeple özellikle production ortamı için, kubernetes üzerinde naked-pod kullanımından da kaçınmamız gerekiyor. Naked-pod’ların herhangi bir hata durumunda yeniden başlatılmayacağını bilmemiz gerekiyor.
Sanırım deployment’larımızın resource request limitlerini belirleyip kontrol altında tutmak, yapabileceğimiz en iyi şeylerden birisi. Kubernetes’in bize sunmuş olduğu scalability yeteneği her ne kadar harika bir özellik olsa da, dikkatli ve kontrollü ayarlanmamış bir hali ise tüm cluster’daki uygulamaların çalışmamasına sebep olabilir.
Sonuçta CPU ve memory hem uygulamalarımız hem de kubernetes scheduler için birer güç kaynağı.
Bir pod’un tüm available resource’ları consume etmesini konrol altında tutarak, sistemin daha reliable olmasını sağlayabiliriz.
Burada ise dikkat etmemiz gereken iki nokta bulunmaktadır.
Bu tanımlamaları ise helm chart içerisinde aşağıdaki gibi gerçekleştirebiliriz.
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "300m" NOT: CPU kaynakları milicore tipinde belirlenir.
Özellikle memory kaynağını belirlerken memory’nin, sıkıştırılabilir bir kaynak olarak ele alınmadığını ve throttle edilemediğini unutmamalıyız. Yani bir pod memory limitine ulaştığında, terminate edilecektir.
Uygulamalarımızın sağlıklı bir şekilde çalışabilmesi için bir diğer önemli konu ise “liveness” ve “readiness” probe’larının kullanımı.
Bildiğimiz gibi kubernetes default olarak container ready durumuna geçtiğinde, trafiği ilgili pod’a yönlendirmeye başlıyor. Fakat container içerisindeki pod tam anlamıyla trafiği kabul etmeye hazır olmayabilir. Kubernetes’in bu işlemi daha verimli bir şekilde yapabilmesi için “liveness” ve “readiness” probe’ları uygulama özelinde belirlememiz gerekiyor.
Liveness probe’u belirleyerek, kubernetes’e ilgili container’ı herhangi bir hata durumunda ne zaman restart edebileceğini söylemiş oluyoruz. Readiness probe ile de uygulamanın trafiği ne zaman kabul etmeye hazır olacağını belirtiyoruz.
Ayrıca bu probe’leri belirlerken, probe özelinde “timeoutSeconds” veya “initialDelaySeconds” gibi parametreleri de belirleyebilmek mümkün.
livenessProbe:
httpGet:
path: /api/health
port: http
initialDelaySeconds: 20
timeoutSeconds: 30
readinessProbe:
httpGet:
path: /api/health
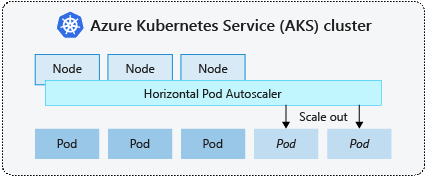
port: http HPA, kubernetes’e deploy ettiğimiz uygulamalar için olmazsa olmaz bir özellik. HPA ile uygulamalarımızı ihtiyaçlar doğrultusunda otomatik olarak scale edebilmek mümkün.
Ayrıca cluster için belirlediğimiz kaynakları da efektif olarak kullanabilmek için ideal bir çözüm.
Uygulamalarımızı CPU ve memory metriklerine göre scale edebilmek için, aşağıdaki gibi ilgili uygulamanın helm chart’ını yapılandırmamız yeterli olacaktır.
“hpa.yaml” dosyasının içeriği:
{{- if .Values.hpa.enabled -}}
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: {{ include "testapp.fullname" . }}
namespace: {{ .Values.namespace }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ include "testapp.fullname" . }}
minReplicas: {{ .Values.hpa.minReplicas }}
maxReplicas: {{ .Values.hpa.maxReplicas }}
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: {{ .Values.hpa.targetCPUUtilizationPercentage }}
- type: Resource
resource:
name: memory
targetAverageValue: {{ .Values.hpa.targetMemoryAverageValue }}
{{- end}} Ardından “values.yaml” dosyasının içerisinde, dilediğimiz auto-scale metriğini aşağıdaki gibi set edebiliriz.
hpa: enabled: true minReplicas: 1 maxReplicas: 3 targetCPUUtilizationPercentage: 70 targetMemoryAverageValue: 256Mi
Tutarlılık için önemli konulardan bir tanesi de, uygulamaların sağlıklı bir biçimde shutdown işlemini gerçekleştirebilmesidir.
Daha önce de dediğimiz gibi, kubernetes üzerindeki uygulamalarımız fâni. Auto-scaling, update işlemleri, pod’un silinmesi gibi herhangi bir durumda container terminate edilebilir.
Bu termination işlemi sırasında ise ilgili pod, farklı veya kritik işlemler de yapıyor olabilir. Bu gibi problemlere engel olabilmek için ise, uygulamalarımızın SIGTERM signal’ını handle ediyor olması gerekmektedir. SIGTERM signal’ı gönderildikten sonra ilgili pod, default olarak 30 saniye içerisinde kendini kapatmalı. Bu süre içerisinde ilgili pod kendisini kapatmazsa, SIGKILL signal’ı gönderilir ve ilgili pod terminate edilir.
Ayrıca default 30 saniye olan graceful termination süresini, “deployment.yaml” dosyası içerisinde pod spec seviyesinde customize edebiliriz.
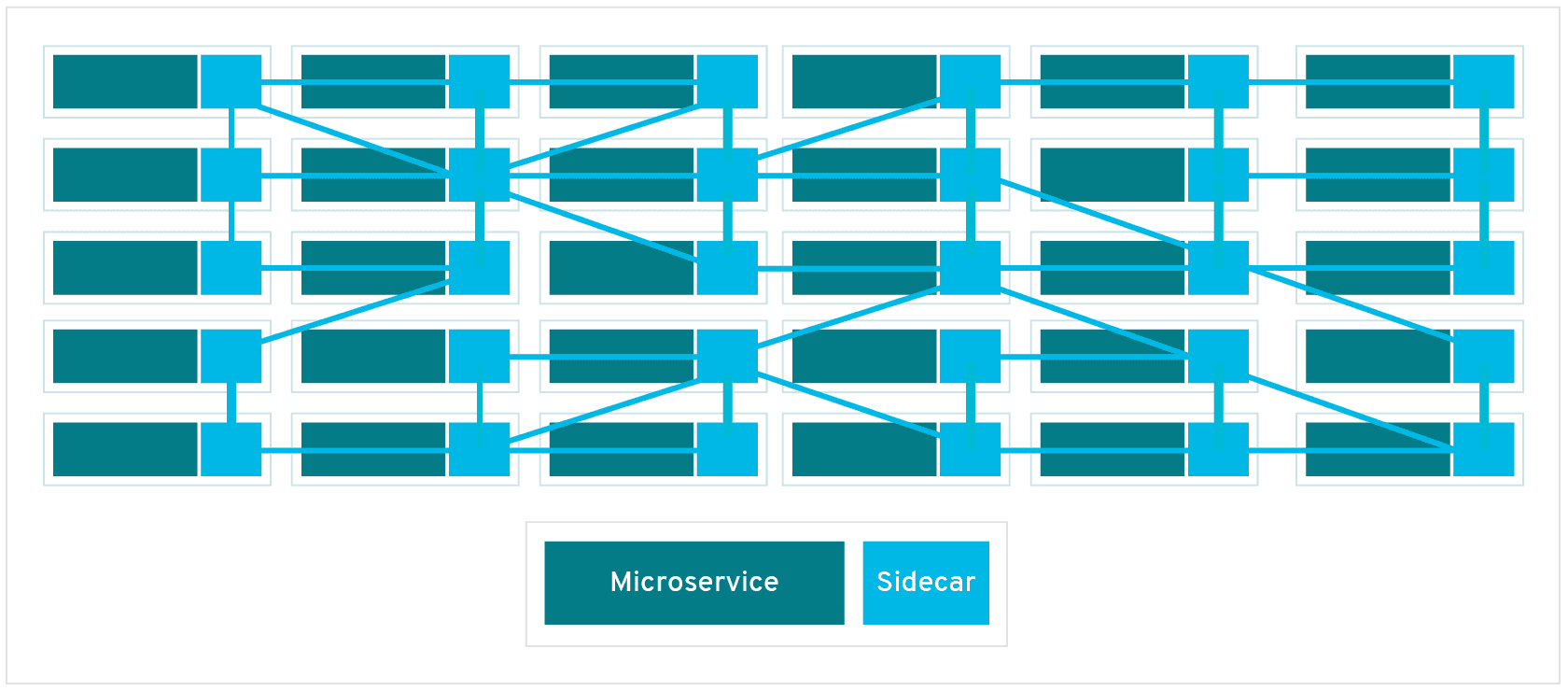
Bildiğimiz gibi service mesh teknolojisinin, özellikle büyük ölçekli microservice ekosistemi içerisinde service-to-service communication’ı için büyük bir rolü bulunmaktradır.
Eğer büyük bir organizasyon içerisinde iseniz bir service mesh teknolojisi kullanmak güvenlik, gözlemlenebilirlik ve dayanıklılık konularında faydamıza olacaktır. Bu konu ile ilgili bir makaleme ise, buradan erişebilirsiniz.
Service mesh’in bir başka faydası ise, long-lived connection’lar için load-balancing işlemlerini gerçekleştiriyor olması. HTTP protokolünün keep-alive özelliğini kullandığımızda, TCP connection’ı bir sonraki request’ler için de açık bırakılır. Yani aynı pod ilgili request’leri handle eder. Aslında throughput ve latency’den kazanırken, scaling’den kaybediyoruz.
Service mesh gibi teknolojileri kullanarak, bu gibi problemlerin de önüne geçebilmek mümkün.
Bildiğimiz gibi container’ların güvenliği, bizim sorumluluğumuz altında. Production ortamları için CNCF içerisinde bulunan Falco Project gibi bir container security activity monitör’üne sahip olmak, her türlü faydamıza olacaktır.
Bu sayede container içerisinde bir shell çalıştırılması veya dışarıya bir network connection’ı kurulması gibi uygulamalarımızdaki beklenmedik aktivitelerden haberdar olabiliriz.
https://kubernetes.io/docs/concepts/configuration
https://learnk8s.io
Nowadays wherever I look, everyone talks about AI coding agents, agentic systems or LLM powered…
In the first two parts of this DevEx series, I tried to show how golden…
In the first part of this DevEx series, I tried to explain Platform Engineering and…
As an architect involved in platform engineering and DevEx transformation within a large-scale organization for…
{:en}In today’s technological age, we typically build our application solutions on event-driven architecture in order…
{:tr} Makalenin ilk bölümünde, Software Supply Chain güvenliğinin öneminden ve containerized uygulamaların güvenlik risklerini azaltabilmek…
{kind=link}
{kind=link}
{kind=link}
View Comments
süper bilgiler teşekürler hocam. Bu arada bir konu hakkında birşey sorucaktım. Bir microservice yapım var localde docker üzerinde çalıştırıyorum. Api gateway olarak Ocelot kullandım ama bu yapıyı Kubernetes e taşımak istiyorum. Api gateway olarak ocelot kullanmalı mıyım ? Ingress ile dışarıya açtım diyelim Gateway i ancak Ocelot tüm servicelere ip ile bağlanıyor direk veya docker compose daki service name ile.. Bunlara kubernetes service nameler ile bağlanmalıyım ki scale edebileyim. Burası karışık kafamda. ApiGateway kısmı nasıl olmalı sizce ?