Genelde hayatımızdaki bütün işlerin, her zaman iyi bir şekilde yolunda gitmesini bekleriz/isteriz. (Aslında kim beklemez ki?) Maalesef bir çok zaman ise, işler beklediğimiz, planladığımız veya umduğumuz gibi olmuyor, iyi bir şekilde yolunda gitmiyor.
Bir developer olarak beklentilerimiz, hayatımızda olduğu gibi, geliştirdiğimiz uygulamalarda da aslında her şeyin iyi bir şekilde yolunda gitmesinden yana. Geliştirdiğimiz uygulamaların gerek functional özelliklerinin sorunsuz (bug‘sız) ve müşterinin istediği gibi çalışabilmesi, gerekse de iyi bir şekilde non-functional özelliklere sahip olabilmesini isteriz. Örneğin performans kriteri.
Performans kriteri bir çok zaman kullanıcıları bizim sistemimizde tutabilmemizi sağlayan önemli bir şeydir aslında. Düşünsenize bir e-ticaret sitesinden alışveriş yapacağız ve bir şeyler yolunda gitmiyor. Ürünler sepete eklenmiyor ve response’lar çok geç geliyor. Son kullanıcı gözünden bakarsak, ne kadar da sıkıcı bir durum değil mi?
Uygulamamız çok güzel olabilir fakat performans kriterinin etkileri, uygulamaya kötü bir şekilde yansıyacaktır.
Biz developer’lara ise burada büyük bir iş düşüyor. İyi performansa sahip bir uygulama geliştirmek veya iyileştirmek istiyorsak, uygulamamızın hangi parçasının bottleneck’e düştüğünü biliyor olmalıyız ki o noktaya odaklanabilelim.
Her neyse diyeceğim o ki, “yazılım geliştirme” sadece “programlamadan” ibaret değil. Programlamadan daha fazlası. Geliştirdiğimiz bir uygulama her zaman beklediğimiz gibi davranmayabilir. Beklenmedik zamanlarda performans problemleri yaşanabilir veya insan faktöründen kaynaklı bug’lar meydana gelebilir. Sanırım buradaki asıl nokta ise, kaçınılmaz olan bu gerçekler karşısında nasıl ayakta durabileceğimiz ve üstesinden nasıl gelebileceğimizdir.
Bu arada “beklenmedik zamanların” işe yaradığı farklı konular da var elbette.
Aslında konuyu bağlamak istediğim nokta ise, Grace Hopper‘ında terimlerinde öncülük ettiği “bug” ve “debugging” işlemleri.
Özellikle “debugging” ve “profiling” işlemlerini runtime üzerinde gerçekleştirmek söz konusu olunca, sanırım asıl challenge ozaman bizim için başlıyor.
Bu makale kapsamında ise daha önce “dotnet reconnect()” etkinliğinde de konuşmacı olarak anlatmış olduğum, .NET Core ile geliştirmiş olduğumuz uygulamaların linux üzerindeki debugging ve profiling işlemlerini nasıl gerçekleştirebiliriz konusuna bir kaç örnek use-case ile iki farklı makale serisi olarak genel bir bakış atmaya çalışacağız.
Makale serisi boyunca debugging ve profiling işlemleri sırasında, “Perf“, “LTTng” “gcore“, “FlameGraph” ve “LLDB” gibi tool’lardan yararlanıyor olacağız. Bu 1. makale serisinde ise, “sampling” ve “tracing” kavramlarına bir giriş yapacağız ve perf tool’u ile bir profiling işlemi ardından lttng tool’u ile de bir tracing işlemi gerçekleştireceğiz.
NOT: Makale boyunca, windows ortamında bu tarz işlere yabancı olmadığınız varsayımıyla ilerliyor olacağım.
Debugging & Profiling işlemlerine başlamadan önce, iki farklı kavramdan bahsetmek istiyorum. CPU ölçümü söz konusu olduğunda, iki farklı measurement mode’una sahibiz. Bunlardan birisi sampling, bir diğeri ise tracing‘dir.
Sampling tercih edildiğinde, profiler periyodik olarak ilgili kodun yavaş çalışan kısımlarını bulabilmek için thread’lerin call stack’lerini query’lemektedir. Yani belirli window’larda snapshot’lar almaktadır.
Sampling genelde long running method’larda veya performans bottleneck’lerine karşı ilk kez bir göz atılacaksa, iyi bir seçenektir. Sampling mode’u uygulamaya herhangi bir overhead getirmemektedir ve CPU time’larını elde edebilmek mümkündür. Sampling işleminin tek dezavantajı ise belirli window’larda snapshot’lar aldığı için, tüm call stack’leri capture edememektedir.
Sampling’in aksine tracing mode’u tercih edildiğinde ise, profiler, profile edilen her bir method içinde harcanan thread CPU time’ını kaydedebilmek için method invocation’larını izlemektedir (entry & exit gibi).
Tracing işlemi sampling’in aksine, bize daha detaylı bilgiler sunmaktadır. Burada CPU time’larının yanında, method invocation count’ları da elde edilebilmektedir. Elbette burada bir overhead söz konusudur.
Genelde tracing işlemini belirli senaryolarda veya sampling ile elde ettiğimiz sonuçlar yeterli gelmediği durumlarda tercih edebiliriz.
Perf, linux-based sistemler için performans araştırması yapabilmemizi sağlayan event-oriented bir profiling tool’udur.
Perf, kernel ve hardware event’leri başta olmak üzere, bir çok event için hem tracing hem de sampling konularında yeteneklidir. Ayrıca perf, linux kernel’ının “perf_events” interface’ini temel almaktadır ve “perf_events” e ise attach edebileceğimiz bir çok event source mevcuttur.
Örneğin:
Profiling işlemine başlamadan önce, örnek gerçekleştirebilmemiz için kötü bir uygulamaya ihtiyacımız var. Siz dilerseniz mevcut uygulamalarınız üzerinden de ilerleyebilirsiniz. Sonuç olarak amacımız, uygulamalarımızın CPU activity’lerini gözlemleyebilmek.
Ben örnek gerçekleştirebilmek adına, fazlasıyla CPU consuming’i yapabilecek bir console uygulaması oluşturacağım. Bu console uygulaması kendisine verilen bir dizi sayının, ilgili index’indeki asal sayıyı bulan ve ardından karekök’ünü hesaplayan bir uygulama olacak (Biraz abartmış olabilirim, örneğe odaklanmayalım).
Oluşturmuş olduğum örnek uygulama ise aşağıdaki gibidir.
“PrimeNumberFinderHelper.cs” file’ı:
using System;
namespace PrimeNumberFinder
{
public class PrimeNumberFinderHelper
{
public long FindNthPrimeNumber(int number)
{
int count = 0;
long a = 2;
while (count < number)
{
long b = 2;
int prime = 1;
while (b * b <= a) { if (a % b == 0) { prime = 0; break; } b++; } if (prime > 0)
{
count++;
}
a++;
}
return (--a);
}
}
} ve “Program.cs” file’ı ise aşağıdaki gibidir.
using System;
using System.Linq;
using System.Threading;
namespace PrimeNumberFinder
{
class Program
{
static PrimeNumberFinderHelper _primeNumberFinderHelper;
static void Main(string[] args)
{
int[] numbers = GetNumbersFromArgs(args);
for (int number = 0; number < numbers.Length; number++) { Console.WriteLine("Finding {0}nth prime number...", numbers[number]); _primeNumberFinderHelper = new PrimeNumberFinderHelper(); long nthPrimeNumber = FindNthPrimeNumber(numbers[number]); Console.WriteLine("{0}nth prime number is {1}.", numbers[number], nthPrimeNumber); double squareRootOfNthPrimeNumber = FindSquareRootOfNthPrimeNumber(nthPrimeNumber); Console.WriteLine("Square root of {0}nth prime number is {1}.", numbers[number], squareRootOfNthPrimeNumber); } Console.WriteLine("Done!"); } private static int[] GetNumbersFromArgs(string[] args) { return args.Select(x =>
{
(bool, int) input = CheckIsItANumber(x);
if (input.Item1)
{
return input.Item2;
}
return default(int);
}).ToArray();
}
//Some child methods for profiling callchain.
static double FindSquareRootOfNthPrimeNumber(double nthPrimeNumber)
{
double squareRoot = 0;
squareRoot = Math.Sqrt(nthPrimeNumber);
Thread.Sleep(10000);
return squareRoot;
}
//Some child methods for profiling callchain.
static long FindNthPrimeNumber(int number)
{
//CPU intensive sample for profiling with perf on linux.
long nthPrimeNumber = _primeNumberFinderHelper.FindNthPrimeNumber(number);
return nthPrimeNumber;
}
//Some child methods for profiling callchain.
static (bool, int) CheckIsItANumber(string num)
{
int? result = null;
try
{
result = int.Parse(num);
}
catch (System.Exception ex)
{
Console.WriteLine("Exception occured while parsing.");
}
return (result != null, result.GetValueOrDefault()); // It can be cause wrong business logic.
}
}
} CPU intensive çalışacak ve call chain’i görebileceğimiz örnek console uygulamamız yukarıdaki gibidir.
Perf ile profiling işlemine başlamadan önce, bilmemiz gereken bir nokta var. Perf, diğer debugging tool’larında da olduğu gibi, bizlere anlamlı bir sonuç verebilmesi için “symbol” bilgilerine ihtiyaç duymaktadır. Tıpkı “pdb” file’ları gibi.
Bu sayede profile işlemi sonucunda elde edeceğimiz bellek adresleri, bizlerin anlayabileceği bir şekilde “method name” ve “variable name’lere” dönüşecektir. Aksi halde C# gibi compiled dillerde sadece hexadecimal değerleri görürüz.
Symbol bilgilerini sağlayabilmek için enable etmemiz gereken bir environment değeri bulunmaktadır. “COMPlus_PerfMapEnabled” değerini enable ettiğimizde, CoreCLR‘a debug bilgilerini perf’ün kullanabilmesi için vermesi gerektiğini söylemiş oluyoruz.
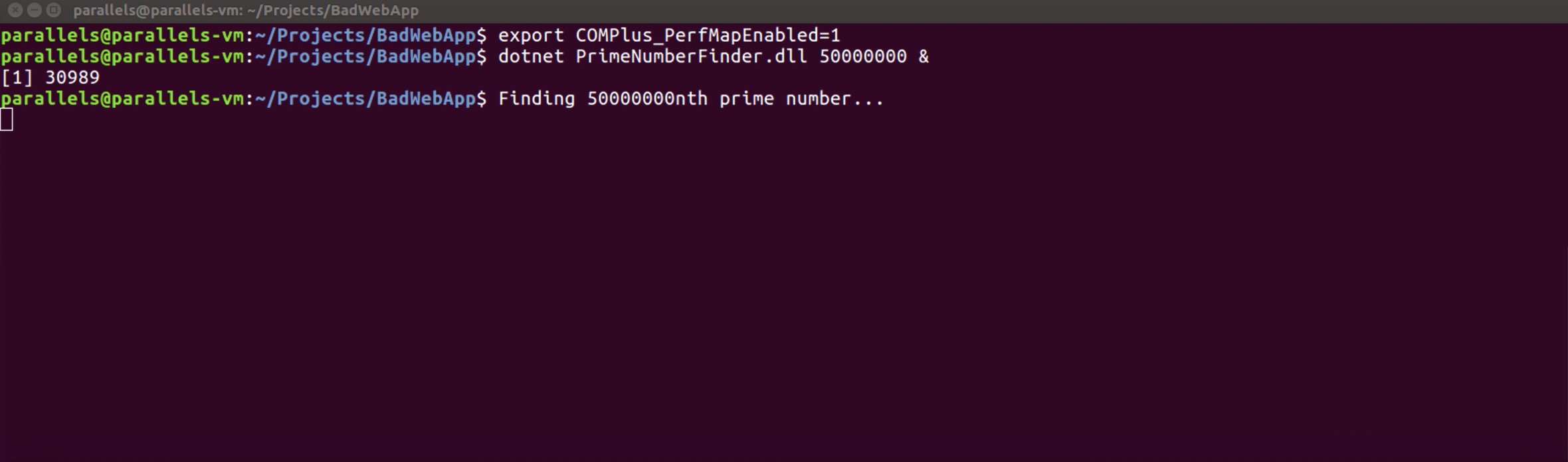
Şimdi environment değerini aşağıdaki gibi enable edelim ve console uygulamamızı çalıştıralım.
Environment değerini enable ettik ve uygulamayı bi hayli zorlayacak bir asal sayıyı bulmasını söyledik.
Peki şimdi sistem ne durumda?
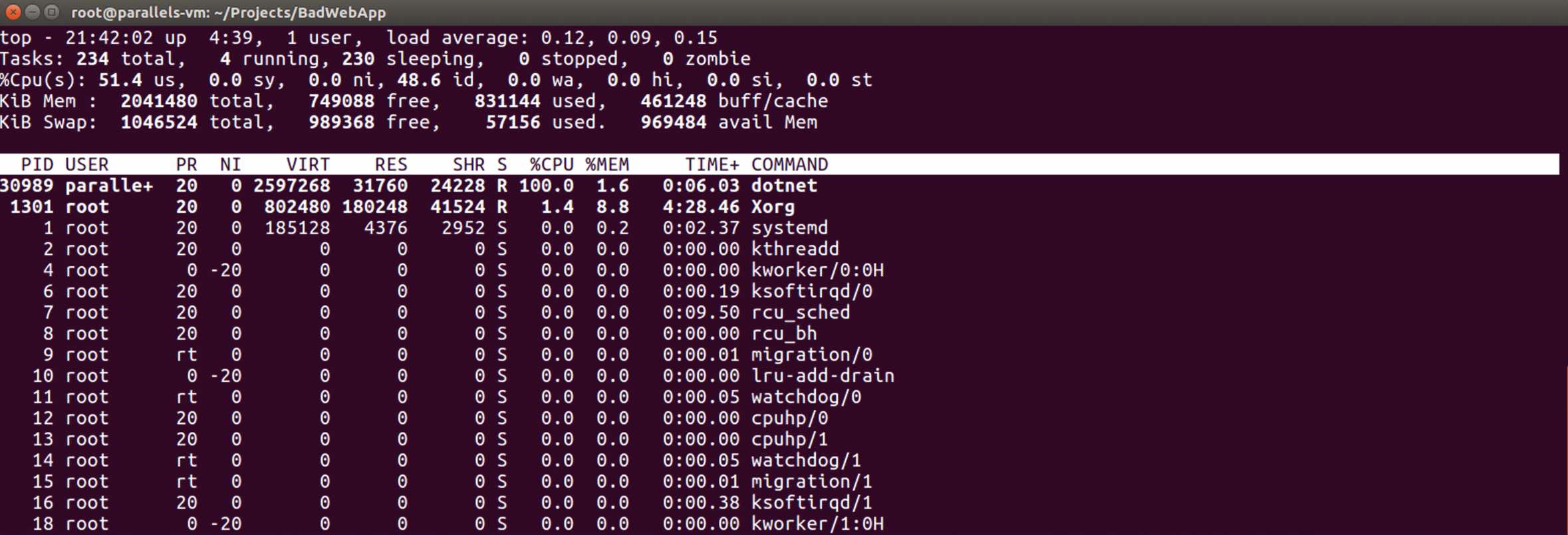
Hemen “top” command’ını yazalım ve process’lere bir bakalım.
Gördünüz mü? “30989” id’li process, CPU‘nun %100 ünü kullanıyor!
Haydi bu process’i bir profile edelim. Bir bakalım uygulamamız nerede bottleneck’e düşüyor ve hangi kod path’ine odaklanmamız gerekiyor.
En basit haliyle, “30989” id’li process için aşağıdaki komut satırı ile bir profiling işlemi başlatalım.
perf record -g -p 30989
NOT: Kullanabileceğimiz farklı parametreler de mevcut. İlgili listeye buradan ulaşabilirsiniz.
Bir kaç saniye içerisinde ise sampling işlemini durduralım. Sonucuna bakarsak, perf, bir kaç saniye içerisinde “4.078” MB’lık “19558” adet sample elde edebilmiş. Bu elde ettiği sonuçları ise, “perf.data” isimli bir file’a yazmış.
NOT: Eğer çok sık çağrılan bir event dinleniyorsa, “perf.data” file’ının boyutu oldukça büyük olacaktır. Bunun yerine, “Memory Mapped Buffer” ı kullanarak real-time olarak profiling işlemini gerçekleştirebilmek de mümkündür.
Elde etmiş olduğumuz bu “perf.data” dosyasını ister aynı makina üzerinde, isterseniz de farklı bir makinaya taşıyarak analiz etme işlemini gerçekleştirebilirsiniz.
Peki, elde etmiş olduğumuz bu profiling sonucunu nasıl yorumlayabiliriz? Yine en basit haliyle, aşağıdaki komut satırını çalıştırarak.
perf report -f
NOT: Profiling sonucunu yorumlarken herhangi bir regular user veya root user karmaşası yaşamamak adına, “-f” parametresi ile herhangi bir ownership doğrulamasının yapılmamasını sağlayabiliriz.
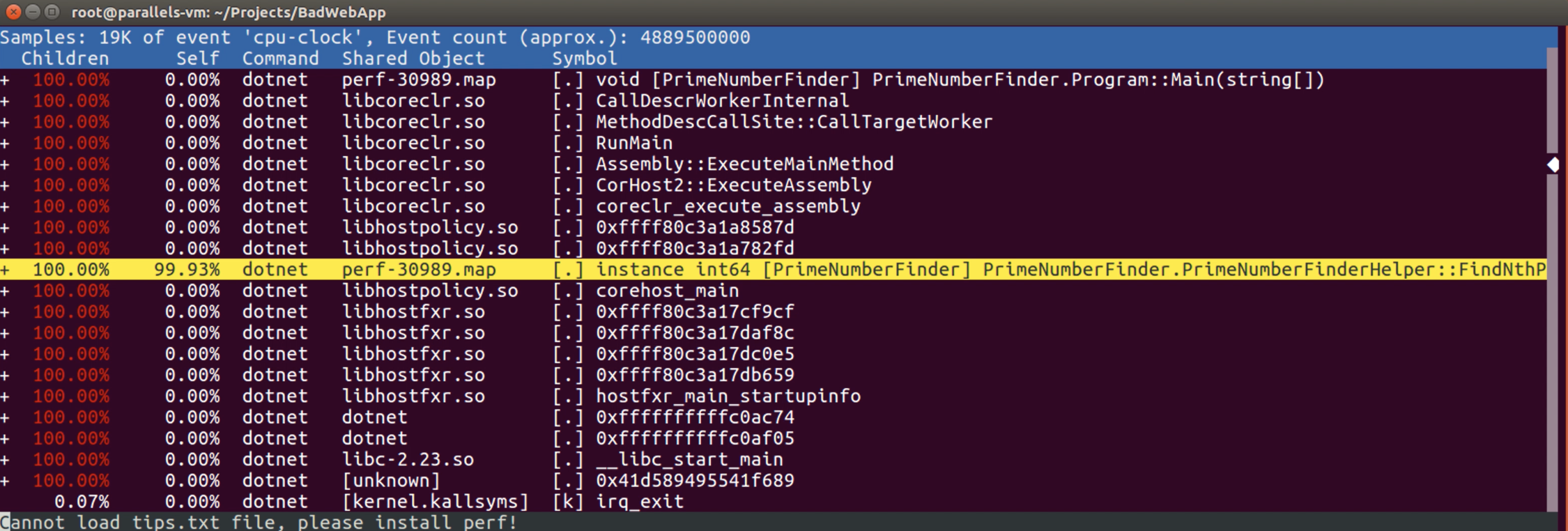
Evet, “30989″ id’li process’in profiling sonucu artık karşımızda. Yukarıdaki sonuç üzerinden, process’in call stack’leri üzerindeki CPU activity’lerini görebilmek mümkündür. “Symbol” kısımlarına dikkat edersek, bizi ilgilendiren noktaların method name ve variable name’lere dönüştüğünü görebiliriz.
“Children” kısmı subsequent call’ların overhead’lerini göstermektedir. İlk satıra bakarsak, “Children” kısmının %100 olduğunu, fakat “Self” kısmının %0 olduğunu görebiliriz. Yani “Children” kısmı bize diyor ki, “ben maliyetli bir yolda ilerliyorum, fakat o maliyetli yol şu an burası değil”. “Self” kısmı ise, o maliyetli kısmın olduğu yer.
Highlight yaptığım satıra bakarsak, “Self” değerinin %99.93 olduğunu görebiliriz. Bu process için CPU consuming’inin gerçekleştiği noktanın, “PrimeNumberFinderHelper” class’ı içerisindeki “FindNthPrimeNumber” method’unda gerçekleştiğini söyleyebiliriz. Bizim bir developer olarak odaklanmamız gereken nokta!
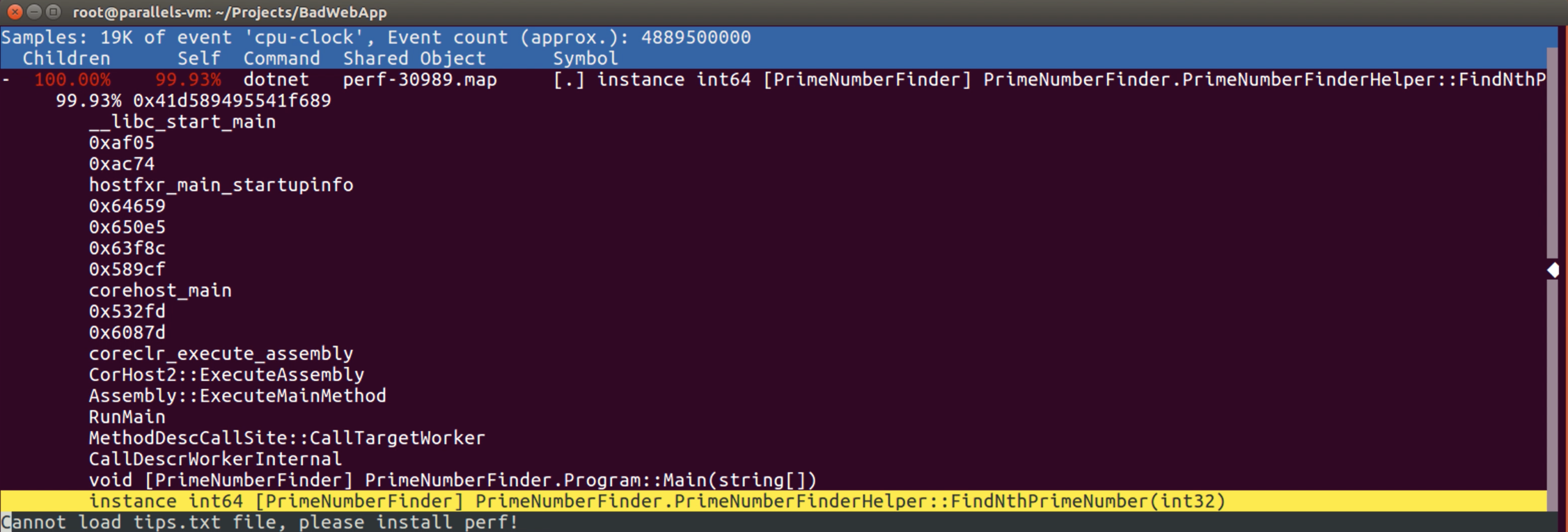
Peki, bu “PrimeNumberFinderHelper” instance’ı nerede kullanılıyor? Haydi biraz daha kazıyalım, call’lara bakalım! Bunun için highlight edilmiş satırın üzerinde, “enter” tuşuna basmamız yeterli olacaktır.
Bottleneck’in olduğu tree’nin en alt kısmına bakarsak, kod akışının “PrimeNumberFinder.Program::Main” method’undan geçtikten sonra, “PrimeNumberFinderHelper” class’ının instance’ı üzerinden “FindNthPrimeNumber” method’unu call ettiğini görebiliriz.
NOT: Perf‘ün “report” command’ında da kullanılabilecek bir çok farklı parametreler mevcuttur. Örneğin verbose seviyesini arttırabilirsiniz, symbol bilgileri resolve edilmeyenleri gizleyebilirsiniz veya call graph’i farklı parametrelere göre görüntüleyebilirsiniz. Detaylı listeye buradan erişebilirsiniz.
En basit haliyle, process üzerinde bir sampling işlemi gerçekleştirerek problemli noktamızı belirlemiş olduk. Artık bir developer olarak odaklanmamız gereken noktayı biliyoruz.
Runtime event’lerinin tracing konusunda ise lttng tool’undan yararlanacağız. LTTng, CoreCLR‘ın build-time’da generate ettiği tracepoint’leri kullanarak, user-space event’lerini handle etmektedir (yani runtime service’leri ve application-level event’ler gibi).
LTTng, windows tarafındaki ETW (Event Tracing for Windows) event’lere benzer bir şekilde, daha zor yani daha derinlemesine problemleri ele alabilmemize olanak sağlayan lightweight bir tracing framework’üdür.
Ne yazıkki ETW events, linux ortamında bulunmamaktadır. ETW event’lere benzer bir şekilde tracing işlemlerini linux ortamında ise lttng framework’ü ile gerçekleştirebilmekteyiz.
LTTng ile trace edebileceğimiz bazı event’lere bakarsak:
gibi event’leri trace edebilmek mümkündür. Perf‘de olduğu gibi trace file’ı ister aynı makina üzerinde istersek de başka bir makina üzerinde analyze edebilmek mümkündür.
Peki, az laf çok iş diyelim ve uygulamaya geçelim.
LTTng ile gerçekleştireceğimiz örnek senaryoda ise bir API‘ımız olduğunu ve bu API‘ın, memory’sini efficient bir şekilde kullanması gerektiğini düşünelim.
LTTng ile tracing işlemine başlamadan önce enable etmemiz gereken bir environment değeri bulunmaktadır. “COMPlus_EnableEventLog” değerini enable ettiğimizde, CoreCLR‘a event log’ları kullanabilmemiz için generate etmesini söylemiş oluyoruz.
Örnek API‘ın kaynak kodlarına ise buradan ulaşabilirsiniz. Perf ile gerçekleştirmiş olduğumuz örneğe benzemektedir. Bu API içerisindeki “api/calculate” endpoint’ine bir dizi sayılar göndereceğiz ve ardından API içerisinde oluşan object allocation‘lara bir bakacağız.
Kullanacağımız komut satırları ise aşağıdaki gibidir.
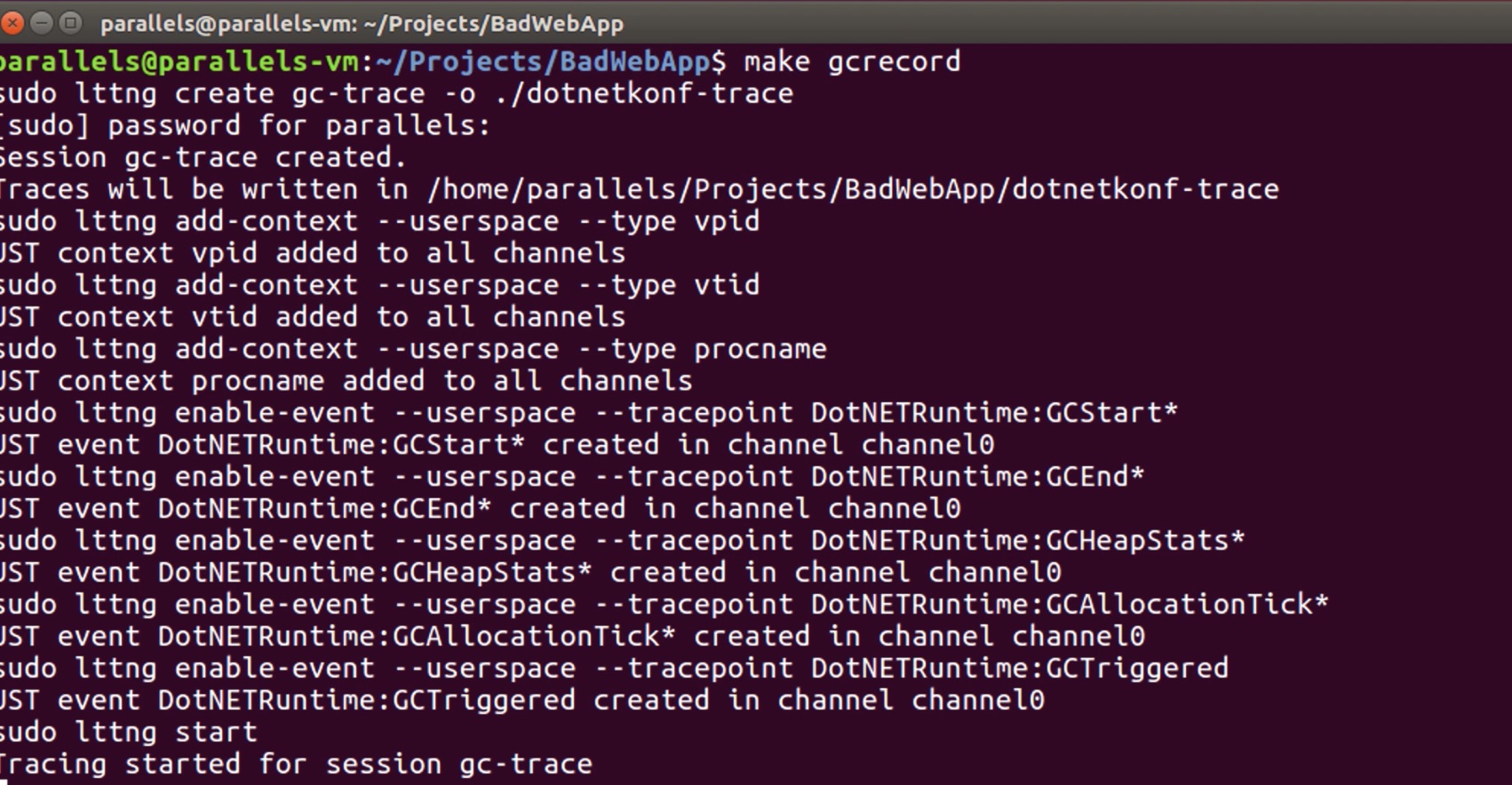
sudo lttng create gc-trace -o ./dotnetkonf-trace sudo lttng add-context --userspace --type vpid sudo lttng add-context --userspace --type vtid sudo lttng add-context --userspace --type procname sudo lttng enable-event --userspace --tracepoint DotNETRuntime:GCStart* sudo lttng enable-event --userspace --tracepoint DotNETRuntime:GCEnd* sudo lttng enable-event --userspace --tracepoint DotNETRuntime:GCHeapStats* sudo lttng enable-event --userspace --tracepoint DotNETRuntime:GCAllocationTick* sudo lttng enable-event --userspace --tracepoint DotNETRuntime:GCTriggered sudo lttng start sleep 20 sudo lttng stop sudo lttng destroy
İlk komut satırında “gc-trace” adında bir session oluşturmasını ve ilgili tracing çıktılarını “dotnetkonf-trace” path’i altında toplaması gerektiğini söyedik. Sonraki satırlarda ise “lttng add-context” parametresi ile, her bir event’in “process id“, “thread id” ve “process name” gibi bilgilere sahip olmasını istediğimizi belirttik.
En önemlisi ise “lttng enable-event” parametresi ile, trace etmek istediğimiz tracepoint’leri tanımladık. Bu sayede CoreCLR tarafından generate edilecek olan “DotNETRuntime:GCStart*” ve “GCAllocationTick*” gibi önemli event’leri trace edebileceğiz. Tüm bunların ardından tracing işlemini başlatıyoruz ve “20” saniye gibi bir süre beklettikten sonra (tracing işlemi, sampling işleminin aksine biraz zaman gerektiren bir işlemdir) işlemi durdurup, session’ı destroy ediyoruz.
NOT: Bu komutların hepsini tek tek yazmak elbette zor olacaktır. Bu sebeple dilerseniz sizde benim yararlandığım makefile’a buradan erişebilir ve kullanabilirsiniz.
Tracing işlemini başlatmadan önce aşağıdaki gibi örnek API‘ı çalıştıralım ve “api/calculate?nums=100,200,300,400,500” URL‘ine biraz istek gönderelim. Ben istek gönderme işlemini Apache Bench vasıtasıyla gerçekleştireceğim.
ab -n 10000 localhost:5000/api/calculate?nums=100,200,300,400,500
İstek gönderme işlemi devam ederken yani uygulamamız aktif olarak çalışırken, tracing işlemini aşağıdaki gibi başlatalım.
Tracing işlemi 20 saniye bekledikten sonra duracaktır.
Peki “dotnetkonf-trace” path’i altında toplanan tracing sonuçlarını nasıl yorumlayabiliriz? İlk seçenek olarak, default gelen simple bir viewer olan babeltrace‘i kullanabiliriz.
Dilerseniz daha user-friendly olan, Eclipse Trace Compass ürününü de kullanabilirsiniz. Tracing sonuçları CTF(Common Trace Format) formatında çıktığı için, Trace Compass ile görsel olarak da görüntüleyebilmek mümkündür.
Her neyse, aşağıdaki komut satırı ile tracing sonucuna bakmaya başlayalım.
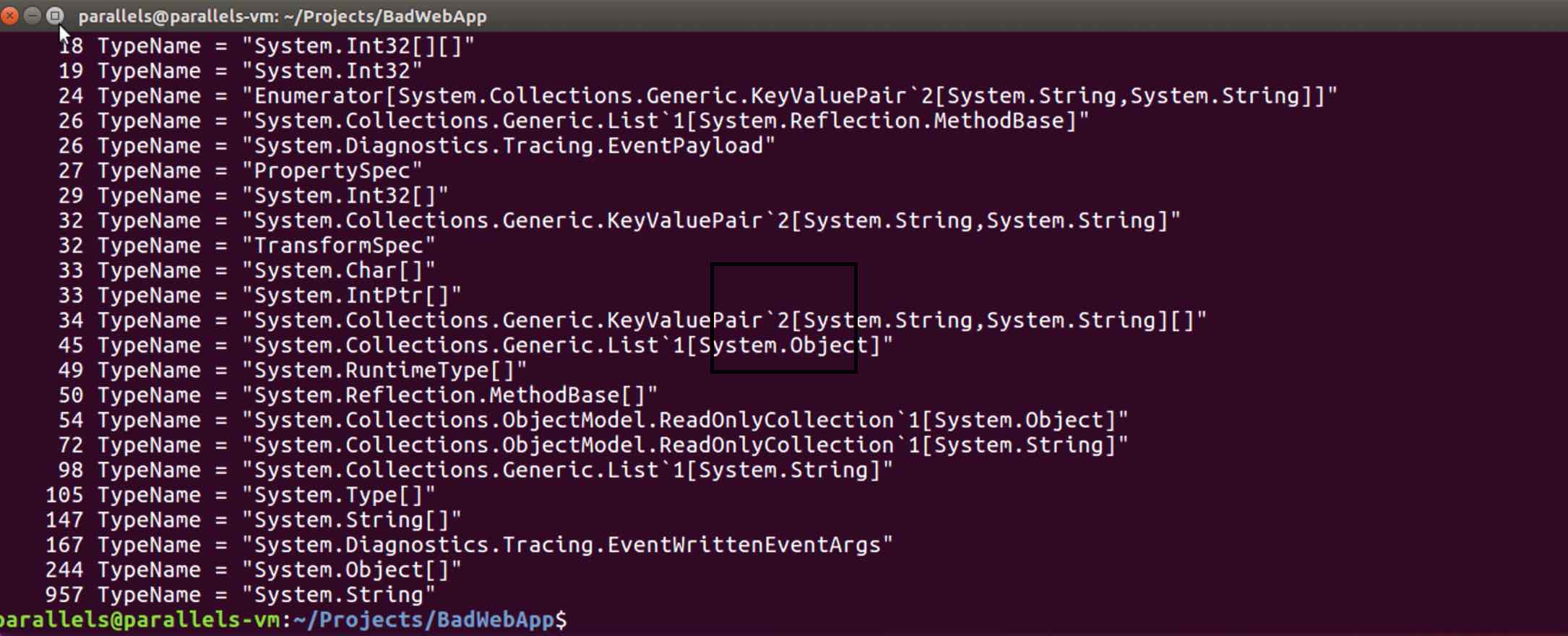
sudo babeltrace ./dotnetkonf-trace | grep GCAllocationTick* | grep 'TypeName = "[^"]*"' -o | sort | uniq -c | sort -n
ve sonuç karşımızda.
Sizlerinde gördüğü gibi 20 saniye gibi bir süre içerisinde, 957 adet “System.String” ve 244 adet “System.Object[]” gibi object’ler API içerisinde allocate edildi. Bu arada, buradaki bilmemiz gereken nokta ise, bu sonuçlar her bir allocation’ın sonucu değildir. Yaklaşık 100KB‘a ulaşan allocation’ların sonucudur.
Peki, bu object allocation’lar nereden geliyor? Bunların bir call stack bilgileri yok mu diye düşünüyorsanız, doğru yoldasınız. Maalesef user-space için lttng‘nin stack trace supportu henüz bulunmamaktadır. (Sanırım 2.11 release içerisinde planlıyorlar: LTTng milestone)
Stack trace bilgilerine erişebilmenin ise bir kaç farklı yöntemi vardır. Sasha Goldshtein‘in güzel bir makalesi var bu konuda. Bu yöntemler ile birlikte core dump analiz işlemlerini de bir sonraki makalemde bende değiniyor olacağım.
Takipte kalın.
https://www.embedded.com/design/operating-systems/4401769/Device-drivers-in-user-space
http://www.brendangregg.com/perf.html
https://lttng.org/docs/v2.10/
http://blogs.microsoft.co.il/sasha/2017/03/30/tracing-runtime-events-in-net-core-on-linux/
https://lttng.org/blog/2018/08/28/bringing-dotnet-perf-analysis-to-linux/
Nowadays wherever I look, everyone talks about AI coding agents, agentic systems or LLM powered…
In the first two parts of this DevEx series, I tried to show how golden…
In the first part of this DevEx series, I tried to explain Platform Engineering and…
As an architect involved in platform engineering and DevEx transformation within a large-scale organization for…
{:en}In today’s technological age, we typically build our application solutions on event-driven architecture in order…
{:tr} Makalenin ilk bölümünde, Software Supply Chain güvenliğinin öneminden ve containerized uygulamaların güvenlik risklerini azaltabilmek…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}