Merhaba arkadaşlar.
Bir önceki Apache Kafka Serisi 01 – Apache Kafka’ya Giriş makalesinde, Apache Kafka’nın ne olduğuna dair kabaca bir giriş yapmış ve terminolojisinden bahsetmiştik. Bu makale kapsamında ise aşağıdaki konulara değineceğiz:
- Zookeeper nedir
- Docker üzerine zookeeper kurulumu
- Docker üzerine kafka kurulumu
- C# client’ı ile kafka üzerinde örnek
![]()
Kurulum işlemine başlamak için Docker Quickstart Terminal’i açalım ve aşağıdaki komut satırını çalıştıralım.
docker search kafka
Komutunu çalıştırılmasından sonra Docker Hub üzerinde bir den çok Kafka image’i olduğunu görebilirsiniz. Ben aşağıdaki image’lerden “ches/kafka” olanını kullanacağım.
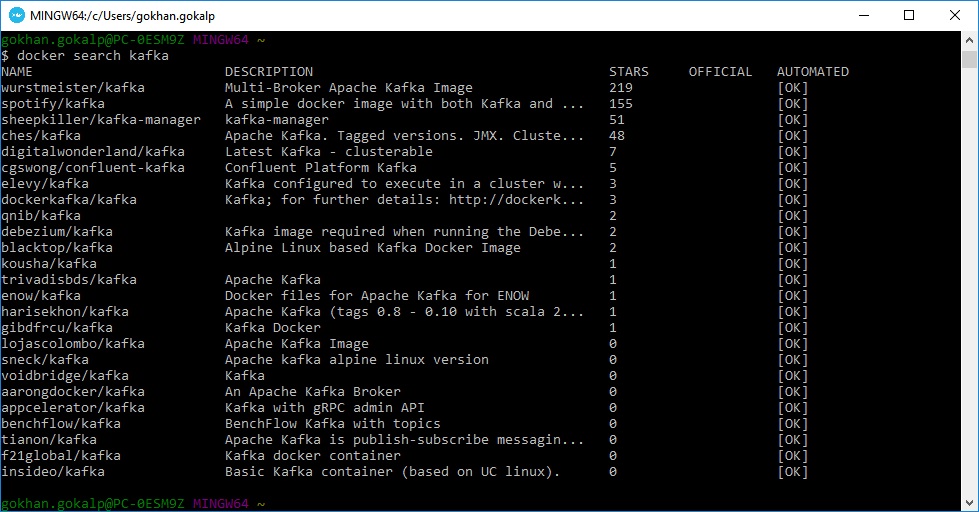
Bu image’in detaylarına ise buradan ulaşabilirsiniz. Kendisi zookeeper bağımsız bir service olarak çalışmaktadır ve configuration’ları parameterized bir hale getirilmiştir.
Dilerseniz biraz zookeeper’dan bahsedelim.
1) Zookeeper Nedir?
Zookeeper ne yapar? Kısaca zookeeper, distributed uygulamalar geliştirmeye izin veren, distributed bir koordinasyon servisidir diyebiliriz. Bir başka değişle, multiple instance’lı distributed sistemleri configure etmeye yarayan open-source bir projedir diyebiliriz. Bu proje hadoop altında geliştirilmeye başlayıp, sonrasında ise üst seviye bir Apache projesi haline gelmiştir.
Zookeeper’ın ne olduğundan biraz bahsettiğimize göre dilerseniz bunun Kafka ile ne alakası var kısmına bir bakalım.
Kafka’ya giriş makalesinde de bahsettiğimiz gibi kafka, tamamen distributed bir sistem üzerinde ve çalışmaktadır. Kafka ise burada zookeeper’ı çeşitli configuration bilgilerini store etmek için kullanmaktadır. Evet, bu cümleden, kafka’nın zookeeper ile beraber çalışmasının zorunlu olduğunu çıkartabiliriz. Kafka Getting Started documentation’a baktığınızda ise zaten şu cümleye denk geleceksiniz:
Step 2: Start the server
Kafka uses zookeeper so you need to first start a zookeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node zookeeper instance.
Kafka broker’ları membership & failure detection, leader seçimi gibi konularda zookeeper’ı kullanmaktadır. Kafka’nın zookeeper ile ne tür bilgiler tuttuğunu merak ediyor iseniz, buraya bakabilirsiniz.
2) Docker Üzerine Zookeeper Kurulumu
![]()
Zookeeper’sız bir kafka kullanamayacağımızdan bahsettiğimize göre, docker üzerinden öncelikle aşağıdaki komut ile “jplock/zookeeper” image’ini download edelim ve container’ı ayağa kaldıralım.
docker run -d --name zookeeper --publish 2181:2181 jplock/zookeeper:latest
“-d” komutu ile container’ın arkaplanda çalışması gerektiğini, isminin zookeeper olacağını ve “–publish” komutu ile de container’ın “2181” port’unu host’a publish ediyoruz.
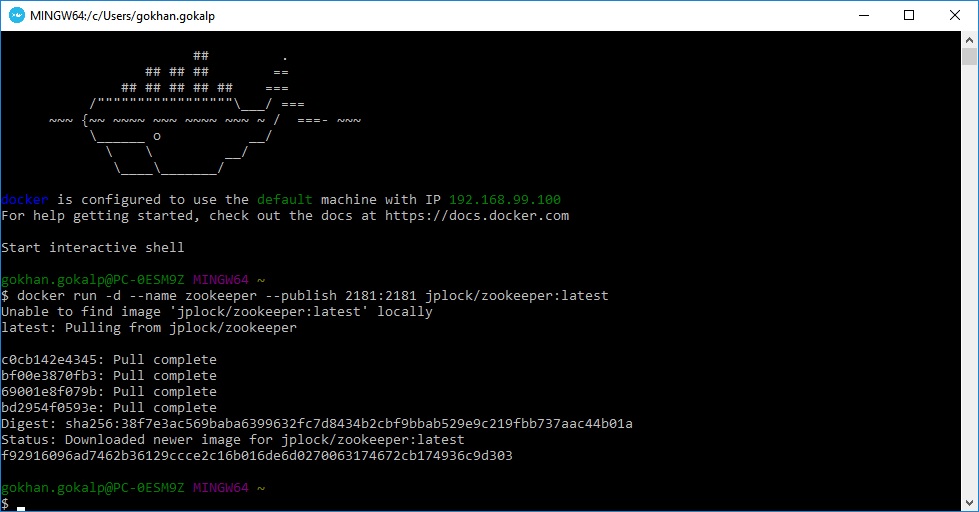
Komutu çalıştırdığımızda “jplock/zookeeper” image’ini bulamadığından, latest versiyonu için docker hub üzerinden pull işlemini gerçekleştirdi ve vermiş olduğumuz configuration bilgileri ile container’ı oluşturdu. Aşağıdaki komutu çalıştırarak aktif olan container’a bir bakalım.
docker ps
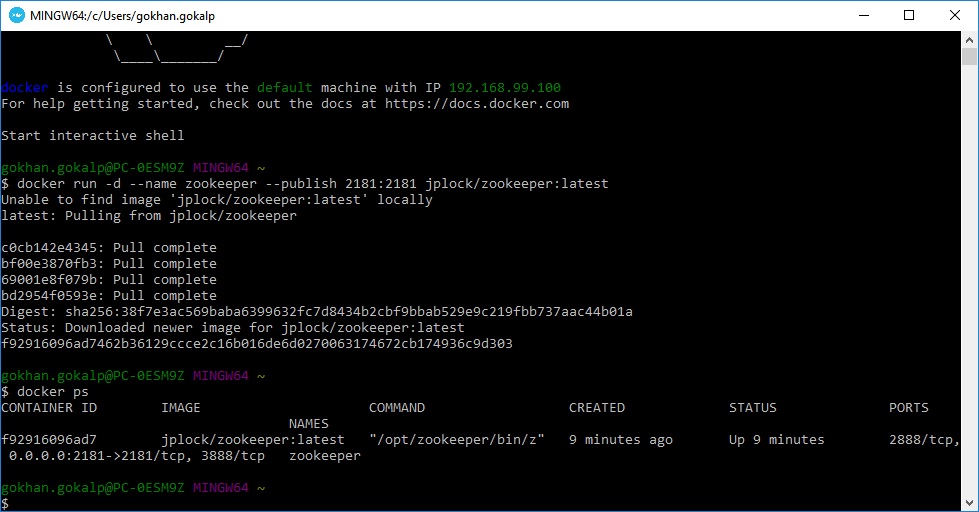
“f92916096ad7” id si ile “zookeeper” isminde container hazır durumdadır. Şimdi kafka kurulumuna geçebiliriz.
3) Docker Üzerine Kafka Kurulumu

Makale girişinde “ches/kafka” image’ini kullanacağımızdan bahsetmiştik. Kurulum sırasında zookeeper’da olduğu gibi ilgili port’u bind edip, kafka container’ını zookeeper’a link’leyeceğiz. Link’leme işlemi sayesinde iki container birbirleri ile konuşabilir hale geleceklerdir.
Kurulum işlemi için aşağıdaki komut satırını terminal üzerinden çalıştıralım.
docker run --name kafka -d -p "9092:9092" -e KAFKA_ADVERTISED_HOST_NAME=192.168.99.100 --link zookeeper:zookeeper ches/kafka
Burada container’a kafka ismini verip, “-p” komutu ile kafka’nın default portu olan “9092” yi host’a bind ediyoruz. Ardından “-e” komutu ile bir “KAFKA_ADVERTISED_HOST_NAME” environment’ı set ediyoruz. Bu değeri docker’ın ip’si olan “192.168.99.100” olarak belirliyoruz. Ip adresi olarak localhost yerine bunu belirtmemizin sebebi ise, kafka’yı multiple brokers çalıştırabilmektir. Linkleme işlemini ise “–link” key’i ile gerçekleştiriyoruz.
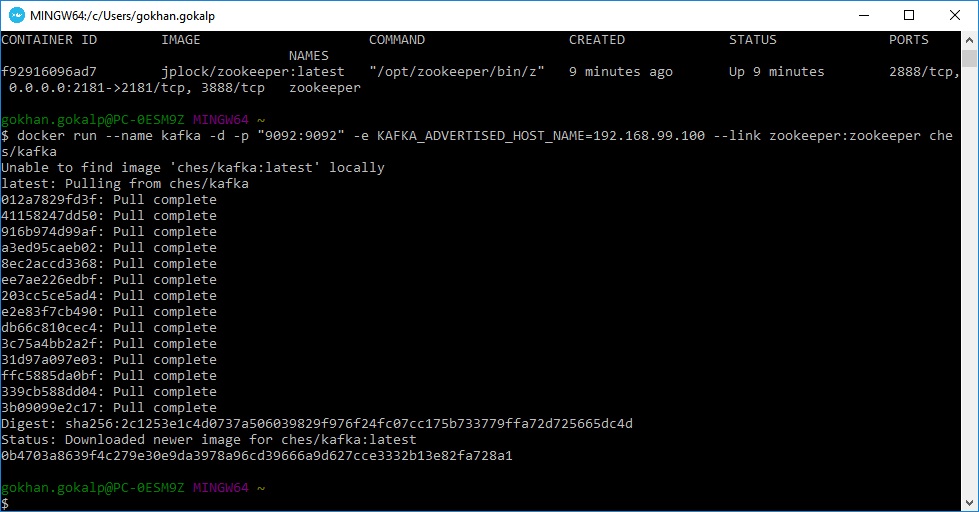
“ches/kafka” image’i daha önce sistemde olmadığı için yine docker hub üzerinden pull işlemleri gerçekleşerek, vermiş olduğumuz configuration ayarları ile birlikte container hazır bir hale gelmiştir. Tekrardan aşağıdaki komutu çalıştıralım ve container’ların son halini bir görelim.
docker ps
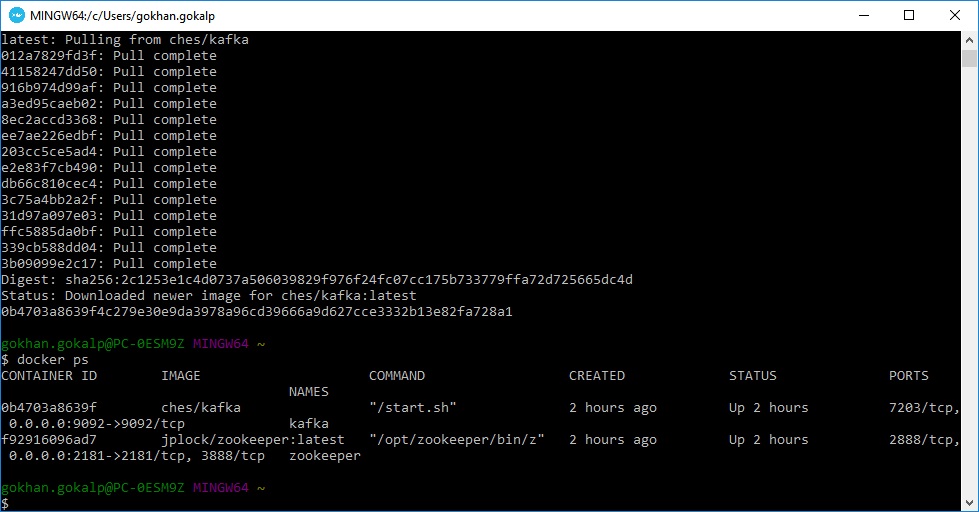
Yukarıdaki resimde gördüğümüz gibi “kafka” ve “zookeeper” isminde iki adet container aktif durumdadır. Docker üzerindeki kurulum işlemlerimizi tamamladık ve artık kafka client’ını kullanarak, “192.168.99.100” numaralı ip si ve bind etmiş olduğumuz “9092” portu üzerinden kafka’ya bağlanabilmeye hazır durumdayız.
4) C# ile Kafka Client Kullanımı
Gerçekleştirecek olduğumuz örnekte Apache Kafka protocol’unu implemente eden, kafka-net isimli kütüphaneyi kullanacağız. Bu kütüphane github üzerinde Jroland isimli bir kullanıcı tarafından geliştirilmektedir.
“KafkaClientExample” isminde boş bir solution oluşturup, içerisine “KafkaProducerExample” isminde bir console application ekliyorum ve ardından Nuget Package Manager’a girerek aşağıda bulunan paketi projeye dahil ediyorum.
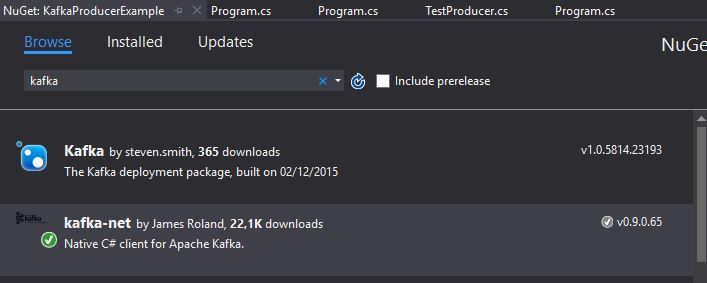
İlgili kafka client paketinin kurulumundan sonra ise “TestProducer” isminde yeni bir class ekleyelim ve isminden de anlaşılabileceği gibi Producer’ı aşağıdaki gibi kodlamaya başlayalım.
using KafkaNet;
using KafkaNet.Protocol;
namespace KafkaProducerExample
{
public class TestProducer
{
private readonly IBrokerRouter _brokerRouter;
public TestProducer(IBrokerRouter brokerRouter)
{
_brokerRouter = brokerRouter;
}
public void SendMessageAsync(string topic, string message)
{
var producer = new Producer(_brokerRouter);
producer.SendMessageAsync(topic, new[] { new Message(message), }).Wait();
}
}
}Constructor aracılığı ile inject etmiş olduğumuz “IBrokerRouter”, message’ların doğru kafka partition kısmına gidebilmeleri için metadata tabanlı routing işlemi gerçekleştirmektedir. “SendMessageAsync” method’u ise “topic” ve “message” parametrelerine sahiptir. Kafka’ya giriş makalesinden hatırlarsak topic’ler kullanıcı tanımlı category isimleri olup, yayınlanacak message’lar burada tutuluyordu. Bu nedenle “SendMessageAsync” method’u içerisinde, message’ın hangi topic’e gideceğini bildirmemiz gerekmektedir.
Method içeriğine baktığımızda “_brokerRouter” ı parametre olarak geçip yeni bir Producer instance’ı oluşturuyoruz. Bu instance üzerinden ise “SendMessageAsync” method’unu çağırıp, hangi topic’e gideceğini ve ilgili message’ı set edip, “Wait” method’u ile ilgili task’ın execution’ının complete olmasını bekliyoruz.
“Program.cs” i ise aşağıdaki gibi kodlayalım.
using System;
using KafkaNet;
using KafkaNet.Model;
namespace KafkaProducerExample
{
class Program
{
static void Main(string[] args)
{
var kafkaOptions = new KafkaOptions(new Uri("http://192.168.99.100:9092"));
var brokerRouter = new BrokerRouter(kafkaOptions);
var producer = new TestProducer(brokerRouter);
Console.WriteLine("Send a Message to TestTopic:");
while (true)
{
producer.SendMessageAsync("TestTopic", Console.ReadLine());
}
}
}
}Bu kısım oldukça straightforward. “KafkaOptions” class’ına bir kafka server uri’ı tanımlıyoruz. Bu uri, kafka kurulumu sırasında docker üzerinden “9092” port adresine bind ettiğimiz docker ip’si. Sonrasında ise oluşturmuş olduğumuz “KafkaOptions” instance’ını kullanarak, bir adet “BrokerRouter” instance’ı yaratıyoruz. “BrokerRouter” instance’ınıda kullanarak “TestProducer” ı tanımlayıp, “SendMessageAsync” method’u ile console üzerinden gelen mesajları “TestTopic” e gönderiyoruz. Artık bir producer’e sahip olduğumuza göre herhangi bir message gönderildiği taktirde, bir adet topic ve bu topic’in x partition’ınında ve x offset’inde bir message’a sahip olacağız. Artık bu topic’i consume etmeye başlayabiliriz.
Solution üzerine “KafkaConsumerExample” isminde yeni bir console application daha ekleyelim ve producer kısmında olduğu gibi Nuget Package Manager üzerinden “kafka-net” kütüphanesini buraya da dahil edelim. Paket dahil etme işleminin hemen ardından “TestConsumer” isimli bir class ekleyelim ve aşağıdaki gibi kodlamaya başlayalım.
using System;
using System.Text;
using KafkaNet;
using KafkaNet.Model;
namespace KafkaConsumerExample
{
public class TestConsumer
{
private readonly IBrokerRouter _brokerRouter;
public TestConsumer(IBrokerRouter brokerRouter)
{
_brokerRouter = brokerRouter;
}
public void StartConsume(string topic)
{
Console.WriteLine($"Consuming {topic}");
var consumer = new Consumer(new ConsumerOptions(topic, _brokerRouter));
foreach (var message in consumer.Consume())
{
Console.WriteLine("Response: PartitionId:{0}, Offset:{1} Message:{2}",
message.Meta.PartitionId, message.Meta.Offset, Encoding.UTF8.GetString(message.Value));
}
}
}
}Buradaki süreç de hemen hemen producer ile aynı. Consumer instance’ı oluştururken, constructor üzerinden extra olarak hangi topic’i consume etmesi gerektiğini söylüyoruz. Oluşan consumer instance’ı üzerinden ise “Consume” method’unu çağırarak, “IEnumerable<Message>” tipinde bitmeyen bir stream elde ediyoruz. Yani sürekli consume modundayız. Consume edilen message’ın “Meta” property’si üzerinden, hangi partition’da olduğunu ve offset bilgisinin ne olduğu gibi spesifik bilgilerede ulaşabilmek mümkündür.
“Program.cs” kısmına geçtiğimizde ise consumer için:
using System;
using KafkaNet;
using KafkaNet.Model;
namespace KafkaConsumerExample
{
class Program
{
static void Main(string[] args)
{
var kafkaOptions = new KafkaOptions(new Uri("http://192.168.99.100:9092"));
var brokerRouter = new BrokerRouter(kafkaOptions);
var consumer = new TestConsumer(brokerRouter);
consumer.StartConsume("TestTopic");
}
}
}“KafkaOptions” üzerinden yine kafka server uri’ını verdikten sonra “TestConsumer” ı initialize ediyoruz ve oluşturmuş olduğumuz “StartConsume” method’una, “TestTopic” ini consume etmek istediğimizi söylüyoruz. Şimdilik hepsi bu kadar.
Dilerseniz iki console uygulamasını da multiple startup olarak başlatalım ve producer üzerinden bir kaç mesaj gönderelim.
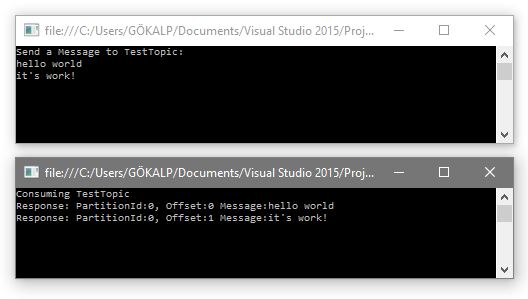
Yukarıdaki resimde gördüğümüz gibi “TestTopic” i üzerinden göndermiş olduğumuz ilk message olan “hello world” message’ı, 0 numaralı partition id’ye ve 0 numaralı offset bilgisine sahiptir. İkinci gönderdiğimiz “it’s work!” message’ı ise, 0 numaralı partition üzerinde, 1 numaralı offset’e sahip olmuştur. Topic’e gelen bu iki message, partition içerisinde sıralı bir şekilde eklenmiştir.
Bir makalenin daha sonuna geldik arkadaşlar. Kafka üzerindeki know-how’ımı arttırdıkça sizlerle paylaşmaya devam edeceğim. Neticede apache kafka büyük bir dünya, hele ki Kafka, Spark ve Avro ekosistemi baz alındığında.
Umarım keyifli bir makale olmuştur. Örnek projeye ekten ulaşabilirsiniz.
Takipte kalın.
MQ yapılarıyla ve kurulumlarıyla ilgili son derece temiz ve kaliteli yazılar oluyor Gökhan hocam, devamı da gelir umarım. RabbitMQ – Kafka yazılarını ve diğer güzel yazılarını fırsat buldukça okuyup referans alıyorum. Emeğin için çok teşekkür ederim.
Serinin devamı gelse çok güzel olur hocam, emeğin için teşekkürler.
C# + kafka +… uygulamasında en basiti ile crud işlemlerinde bir mesaj kuyruğu oluştu.
Örneğin bir kayıt yapıldığında 4 farklı tabloya da kayıt yapılması gerekiyor.
Sırasıyla 1,2,3 ve geldi 4. tabloya.
Her bir tabloda kayıt yapılacak ya da güncellenecek satır sayısı fazla diyelimki 15 er satır kadar var.
Tam 4. tabloya gelindiğinde bir hata oluştu.
4. tablodaki hatada mecburen ilk 3 kayıt iptal edilip tablolar eski haline getirilmek zorunda.
Sonrada kullanıcıya, arkadaş bu kayıt sırasında hata oluştu mesajı verilecek.
Bence en büyük sıkıntı bu bölümde.
Teşekkürler.
Gökhan Bey, Sizin Saga dediğiniz çözüm kendi içinde problemli. Örneğin 3. tabloda sonuç olumsuz. Şimdi ben programın başka alternatifler aramasını istersem Saga bunu karşılamıyor. Saga sadece işlemleri “iddia ettiği üzere” atomik bir yapıda geri alıyor(bu süre zarfında uzak sunucu varsa timeout kaçınılmaz oluyor.). Compansating Transaction türü yaklaşımlar ise loglamalara dayanıyor. Ciddi iş yükü geliyor. Heleki bağımsız çoklu sunucular varsa durum daha da vahim. Sık sık timeout hataları alınıyor. Çünkü işlemler dizisinin geri alınması kısa bir işlem olmuyor. Düşüncem mikroservis ve benzeri mimarilere yaklaşırken çok düşünmek gerekli olduğudur. Bu yapılar kullanılmak isteniyorsa DDD modeli çok iyi öğrenilmeli.
Teşekkürler.